docs4IT
IT organizations are continuously challenged to deliver better IT services at lower cost in a turbulent environment. Several management frameworks have been developed to cope with this challenge, one of the best known being the IT Infrastructure Library (ITIL).
Microsoft® Operations Framework (MOF) is Microsoft’s structured approach to the same goal as ITTL. 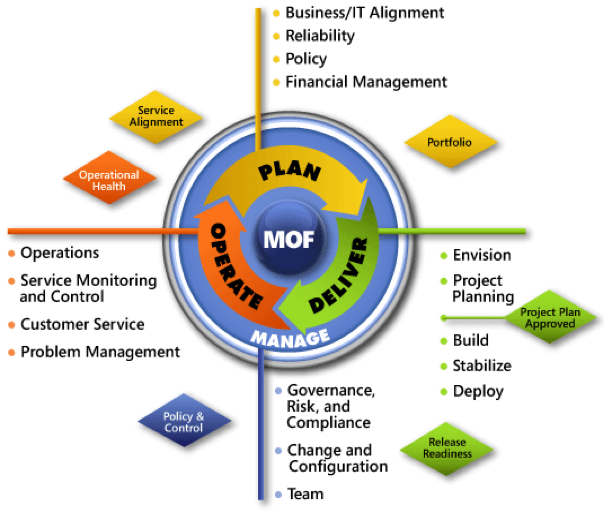
The analysis follows a number of management paradigms that have proven to be essential to IT Service Management:
- Process, People, and Technology (PPT)
- Strategy, Tactics and Operations (STO)
- Separation of Duties (SoD)
- The Strategic Alignment Model Enhanced (SAME)
- Deming’s Plan-Do-Check-Act Management Cycle
At the highest level, both frameworks follow a lifecycle approach, but these lifecycles are somewhat different. ITIL uses five elements for its lifecycle: Strategy, Design, Transition, Operation, and Continual Improvement, which brings it close to the PDCA model. MOF’s lifecycle core consists of only three phases: Plan, Deliver, and Operate, with one underlying layer (Manage) covering the components that apply to all lifecycle phases.
Both ITIL and MOF use processes and functions as building blocks, although the emphasis differs significantly. ITIL labels most of its components as processes and activities (ITIL has 26 Processes and four functions), while MOF is almost entirely based on Service Management Functions (SMFs), each SMF having a set of key processes, and each process having a set of key activities. This rigid structure supports consistency throughout the framework.
In both frameworks, control of the lifecycle progress runs through a number of transition milestones. These milestones have been made very explicit in MOF’s Management Reviews (MRs). Both frameworks apply the PDCA improvement approach throughout the lifecycle. MOF, like ITIL, offers best-practice guidance that can be followed in full but also in part, for addressing a subset of local problems. The “ITSM language” is quite consistent between both frameworks, with only minor differences. But there also are significant differences between the two frameworks.
A remarkable difference is the way customer calls are handled: ITIL separates incident calls from operational service requests and change requests, and MOF combines several customer request types in a single Customer Service SMF. ITIL and MOF also use very different role sets and role titles. This is largely due to the difference in starting points: ITIL works from the best practices documented in each phase, where MOF starts from a structured organization perspective. An area of significant difference can be found in the approach the two frameworks take to technology. A key element of ITIL is that it is both vendor- and solution-agnostic—meaning, the practices encouraged by ITIL can be applied across the board regardless of the underlying technology. The result is that ITIL focuses on the management structure that makes IT successful, rather than on the technology.
Distinctly different, Microsoft has created MOF to provide a common management framework for its platform products, although MOF can easily be used for other platforms.
Another difference is that ITIL is available in five core books that are sold through various channels, while MOF is available on the internet for free, offering practical guidance in various formats. As a consequence, ITIL copyright is highly protected, where Microsoft made MOF content available under the Creative Commons Attribution License, which makes it freely available for commercial reuse.
Finally, ITIL offers a complex certification scheme for professionals, where Microsoft currently limits its certification for MOF to just one MOF Foundation examination. At the time of this writing, plans for further certifications are under consideration, but no final decisions have been made.
The ITIL certification scheme is much more extensive, and, in effect, offers a qualification structure that can offer a potential career path for IT professionals.
Both frameworks show plenty of similarities and can be used interchangeably in practice. Both also have some specific features that may be of good use in a specific case. Main focus of ITIL is on the “what,” where MOF concentrates on the “what” as well as the “how.”
In theory there is no difference between theory and practice. In practice there is.
What is ITIL?
ITIL offers a broad approach to the delivery of quality IT services. ITIL was initially developed in the 1980s and 1990s by CCTA (Central Computer and Telecommunications Agency, now the Office of Government Commerce, OGC), under contract to the UK Government. Since then, ITIL has provided not only a best practice based framework, but also an approach and philosophy shared by the people who work with it in practice.
ITTL - The Service Lifecycle
ITIL Version 3 (2007) approaches service management from the lifecycle of a service. The Service Lifecycle is an organization model providing insight into the way service management is structured, the way the various lifecycle components are linked to each other and to the entire lifecycle system. The Service Lifecycle consists of five components. Each volume of the ITIL V3 core books describes one of these components:
- Service Strategy
- Service Design
- Service Transition
- Service Operation
- Continual Service Improvement
 Service Strategy is the axis of the Service Lifecycle that defines all other phases; it is the phase of policymaking and objectives. The phases Service Design, Service Transition, and Service Operation implement this strategy, their continual theme is adjustment and change. The Continual Service Improvement phase stands for learning and improving, and embraces all cycle phases. This phase initiates improvement programs and projects, and prioritizes them based on the strategic objectives of the organization. Each phase is run by a system of processes, activities and functions that describe how things should be done. The subsystems of the five phases are interrelated and most processes have overlap into another phase.
Service Strategy is the axis of the Service Lifecycle that defines all other phases; it is the phase of policymaking and objectives. The phases Service Design, Service Transition, and Service Operation implement this strategy, their continual theme is adjustment and change. The Continual Service Improvement phase stands for learning and improving, and embraces all cycle phases. This phase initiates improvement programs and projects, and prioritizes them based on the strategic objectives of the organization. Each phase is run by a system of processes, activities and functions that describe how things should be done. The subsystems of the five phases are interrelated and most processes have overlap into another phase.
What is MOF?
First released in 1999, Microsoft Operations Framework (MOF) is Microsoft’s structured approach to helping its customers achieve operational excellence across the entire IT service lifecycle. MOF was originally created to give IT professionals the knowledge and processes required to align their work in managing Microsoft platforms cost-effectively and to achieve high reliability and security. The new version, MOF 4.0, was built to respond to the new challenges for IT: demonstrating IT’s business value, responding to regulatory requirements and improving organizational capability. It also integrates best practices from Microsoft Solutions Framework (MSF).
MOF - IT Service Lifecycle
The IT service lifecycle describes the life of an IT service, from planning and optimizing the IT service and aligning it with the business strategy, through the design and delivery of the IT service in conformance with customer requirements, to its ongoing operation and support, delivering it to the user community. Underlying all of this is a foundation of IT governance, risk management, compliance, team organization, and change management. The IT service lifecycle of MOF is composed of three ongoing phases and one foundational layer that operates throughout all of the other phases:
- Plan phase: plan and optimize an IT service strategy in order to support business goals and objectives.
- Deliver phase: ensure that IT services are developed effectively, deployed successfully, and ready for Operations.
- Operate phase: ensure that IT services are operated, maintained, and supported in a way that meets business needs and expectations.
- Manage layer: the foundation of the IT service lifecycle. This layer is concerned with IT governance, risk, compliance, roles and responsibilities, change management, and configuration. Processes in this layer apply to all phases of the lifecycle.
Main Components
Each phase of the IT service lifecycle contains Service Management Functions (SMFs) that define and structure the processes, people, and activities required to align IT services to the requirements of the business. The SMFs are grouped together in phases that mirror the IT service lifecycle. Each SMF is anchored within a lifecycle phase and contains a unique set of goals and outcomes supporting the objectives of that phase. Each SMF has three to six key processes. Each SMF process has one to six key activities. For each phase in the lifecycle, Management Reviews (MRs) serve to bring together information and people to determine the status of IT services and to establish readiness to move forward in the lifecycle. MRs are internal controls that provide management validation checks, ensuring that goals are being achieved in an appropriate fashion, and that business value is considered throughout the IT service lifecycle.
In terms of the approach, both frameworks use a lifecycle structure at the highest level of design. Furthermore, both use processes and functions, although the emphasis differs significantly; ITIL describes many components in terms of processes and activities, with only a few functions, while MOF is almost entirely based on Service Management Functions. This difference is not as severe as it looks at first hand, since ITIL uses the term “process” for many components that actually are functions.
ITIL follows a phased approach in the lifecycle, and most of the components described in one phase also apply, to a greater or lesser extent, to other phases. The control of the MOF lifecycle is much more discrete, using specific milestones that mark the progress through the various stages in the lifecycle. MOF components that apply to more than one of these three lifecycle phases are separated from the lifecycle phases and described in an underlying Management Layer. Both frameworks are best characterized as “practice frameworks” and not “process frameworks.” The main difference is that ITIL focuses more on the “what,” and MOF covers both the “what” and the “how.”
The modeling techniques of ITIL and MOF are not that much different at first sight: both frameworks use extensive text descriptions, supported by flowcharts and schemes. ITIL documents its best practices by presenting processes, activities, and functions per phase of its lifecycle. MOF components have a rigid structure: each SMF has key processes, each process has key activities, and documentation on SMFs and MRs is structured in a very concise format, covering inputs, outputs, key questions, and best practices for each component. This rigid structure supports consistency throughout the framework and supports the user in applying a selection of MOF components for the most urgent local problems. The activation and implementation of ITIL and MOF are not really part of the framework documentation. ITIL has been advocating the “Adopt and Adapt” approach. Supporting structures like organizational roles and skills are described for each phase, but implementation guidance is not documented. MOF, like ITIL, offers best practice guidance that can be followed in full but also in part, for addressing a subset of local problems. Both frameworks speak of “guidance,” leaving the actual decisions on how to apply it to the practitioner.
Support structures for ITIL are not really part of the core documents: although a huge range of products claim compatibility with ITIL, and several unofficial accreditation systems exist in the field, the core books stay far from commercial products and from product certification, due to a desire to remain vendor-neutral. MOF compatibility, on the other hand, is substantially established. Microsoft aligns a broad set of tools from its platform with the MOF framework. And although MOF is not exclusively applicable for these Microsoft management products, the documentation at Microsoft’s TechNet website provides detailed information on the use of specific products from the Microsoft platform.
Differences
Although ITIL and MOF share many values, the two frameworks also show some significant differences.
- Cost: ITIL is available in 5 core books that are sold through various channels, but MOF is available on the internet for free. As a consequence, ITIL copyright is highly protected, where Microsoft made MOF content available under the Creative Commons Attribution License, which makes it freely available for commercial reuse.
- Development: in the latest versions, both ITIL and MOF spent considerable energy on documenting the development of new services and the adjustment of existing services. In addition, ITIL is constantly reviewed via the Change Control Log, where issues and improvements are suggested and then reviewed by a panel of experts who sit on the Change Advisory Board. The ITIL Service Design phase concentrates on service design principles, where the Deliver Phase in MOF concentrates on the actual development of services. The approach taken in MOF is heavily based on project management principles, emphasizing the project nature of this lifecycle phase.
- Reporting: ITIL has a specific entity that describes Reporting, in the Continual Service Improvement phase, where MOF has integrated reporting as a standard activity in SMFs.
- Call handling: ITIL V2 showed a combined handling of incidents and service requests in one process, but in ITIL V3 incident restoration and service request fulfillment were turned into two separately treated practices. MOF on the other hand stays much closer to the ITIL V2 practice, combining several customer requests in one activity flow, for incident restoration requests, information requests, service fulfillment requests, and new service requests. If the request involves a new or non-standard service, a separate change process can be triggered.
- Lifecycle construction: Most elements of ITIL are documented in one and only one of the five core books, but it is then explained they actually cover various phases of the ITIL lifecycle. ITIL uses five elements for its lifecycle: Strategy, Design, Transition, Operation, and Continual Improvement, which brings it close to the PDCA model. MOF’s lifecycle comprises only three phases: Plan, Deliver, Operate, with one underlying layer covering the components that apply to all lifecycle phases. As a consequence, a number of practices are applied all over the MOF lifecycle, but in ITIL these are mostly described in one or a few lifecycle phases. As an example, risk management is part of the Manage layer in MOF, but in ITIL it is mainly restricted to Strategy and Continual Improvement. The same goes for change and configuration management: throughout the MOF lifecycle but in ITIL these are concentrated in the Transition phase.
- Organization: ITIL describes roles and organizational structures in each lifecycle phase. MOF supports best practices for organizational structures by applying the Microsoft Solutions Framework (MSF) approach: throughout the MOF lifecycle responsibilities are documented and accountability is made explicit, and general rules are allocated to the underlying Manage layer.
- Governance: Both frameworks illustrate the difference between governance and management. ITIL describes governance theory and practice in the Strategy phase and in the CSI phase of its lifecycle, and refers to governance requirements in most other phases. MOF explicitly documents accountability and responsibility in all of its lifecycle phases and in the Manage layer, identifying decision makers and stakeholders, and addressing performance evaluation. MOF specifically addresses risk management and compliance in the Manage layer, supporting governance throughout the lifecycle. Explicit Management Reviews are used throughout the MOF framework as control mechanisms.
Positioning
This section will show how ITIL and MOF are positioned in the main paradigms, as discussed before. Appendix A shows the differences in more detail. Lifecycle On a high level, the lifecycles of ITIL and MOF appear to be rather similar, although the phases cannot be compared on a one-to-one basis.
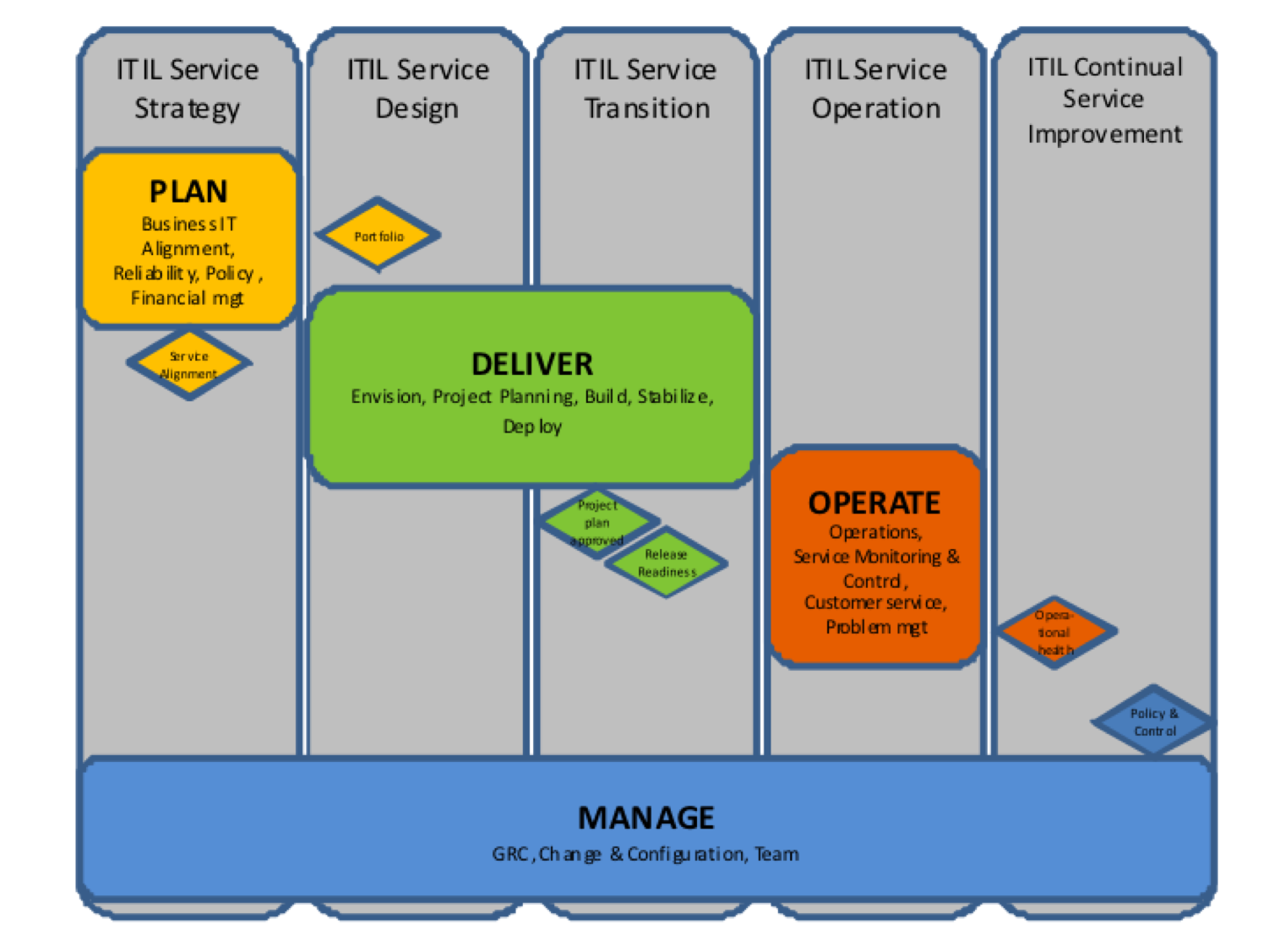
There are some major differences between ITIL and MOF lifecycles:
- ITIL lifecycle phases contain processes, activities, and functions that also apply to other phases. In MOF, the SMFs that apply to more than one phase have been filtered out and grouped in the Manage layer, supporting the entire MOF lifecycle.
- MOF lifecycle phase transitions are managed through several Management Reviews (MRs). These MRs serve to determine the status of IT services and to establish readiness to move forward in the lifecycle. ITIL also uses a number of readiness tests for progress control in the lifecycle phases, but these are less explicit.
People - Process - Technology (PPT)
80 percent of unplanned downtime is caused by people and process issues, including poor change management practices, while the remainder is caused by technology failures and disasters. (Donna Scott, Gartner, Inc., 2003)
Both ITIL and MOF have a strong focus on processes. Both frameworks document the activities that need to be performed to cope with everyday problems and tasks in service organizations. Both frameworks also use the same formal definition of “process,” based on widely accepted ISO standards. However, in both cases the framework documentation is largely presented in a mix of process, people, and some technology, and therefore in the format of procedures, work instructions, and functions. This is for good reasons, because it addresses the actual perception of what people experience in their daily practice. Readers looking for “pure process descriptions” or process “models” will not find these in ITIL nor in MOF. And although ITIL uses the term “process” for many of its components, most of these components are actually functions. MOF uses the term Service Management Function throughout the framework.
Organizational structures are documented quite differently in both frameworks. Individual ITIL roles and MOF roles show some overlap, but both frameworks contain a long list of unique roles. This is largely based on the difference in viewpoint: ITIL works from its practices towards a detailed roles spectrum, and MOF works from a number of basic accountabilities: Support, Operations, Service, Compliance, Architecture, Solutions, and Management. MOF applies the MSF framework as a reference system for these organizational structures, supporting the performance of the organization. In larger organizations the MOF roles can be refined into more detailed structures, but in most organizations the roles are sufficient. The Team SMF of MOF is explicitly focused on the management of IT staff.
Technology is only covered at an abstract level in ITIL: the framework stays far from commercial products and only describes some basic requirements. MOF on the other hand is deeply interwoven with technology solutions. Although MOF has been defined in such a way that it is not technology-specific, the Microsoft technology platform highly aligns with the practices documented in MOF. The MOF website is embedded in the rest of the TechNet documentation on Microsoft products. STO and SoD, in SAME
Strategic levels are covered in both frameworks. ITIL documents its best practices on long-term decisions in the Strategy phase. MOF does the very same in the Plan phase, and supports this in the Manage layer. Tactical levels are covered in a similar way: ITIL concentrates these in the Service Design and CSI phase, and MOF describes its tactical guidance in the Deliver phase, in the Manage layer and in the Operate phase (Problem Management). Operational levels are covered mainly in a single phase in both frameworks; ITIL has its Service Operation phase, and MOF has its Operate phase.
The ITIL lifecycle phases are positioned mainly in the Technology Management domain, emphasizing that ITIL explicitly supports the organizations that deliver IT services. The activities that relate to the specification of the service requirements and the management of enterprise data architectures are typically found in the middle column of the 3x3 SAME matrix.
This also applies to MOF. The MOF Plan phase is largely positioned at the Strategy level, but also concentrates on the Technology Management domain. The Deliver phase is positioned similarly, but then on tactical and operational levels. The Operate phase clearly works at the operational level of the Technology Management domain, except for the very tactical practice of Problem Management. The Manage layer in MOF relates to all three management levels, but also concentrates at the Technology Management domain.
As a consequence, both frameworks require that elements from additional frameworks like TOGAF, ISO27001, CobiT, M_o_R®, BiSL, FSM, and MSP™, are applied for managing the rest of the overarching Information Support domain. Plan-Do-Check-Act (PDCA)
ITIL explicitly follows Demings PDCA management improvement cycle, for implementing the CSI phase, for implementing the Information Security function in the Service Design phase and for the continual improvement of services, processes, and functions throughout the service lifecycle.
MOF does not explicitly list PDCA as a mechanism, but it follows its principles throughout the lifecycle, in all SMFs. Plan-do-check is elementary to the implementation of all SMFs, and various check-act points can be found in the very explicit Management Reviews throughout the MOF framework.
Terminology and Definitions
The “ITSM language” is quite consistent between both frameworks, with only minor differences. For example, where ITIL uses the term Change Schedule, MOF uses Forward Schedule of Change. Such small differences shouldn’t be a problem in practice. Of course both frameworks use some typical terminology that illustrates some of their unique characteristics: • The ITIL core terms utility and warranty, fit for purpose and fit for use, are not used in MOF, and neither are terms like service package – although MOF speaks of “packaged products” in general terms. • Likewise, some explicit MOF terms, like customer service management, stabilize, and issue-tracking, are not used—or are used differently—in ITIL.
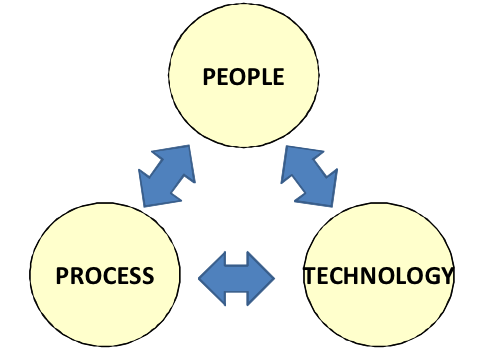 The interrelationship of people, process, and technology. A widely accepted paradigm for defining the core focus areas in managing organizational improvement is Process - People - Technology (PPT). When using IT Service Management frameworks for organizational improvement, each of these three areas should be addressed. An important consequence of applying this paradigm is the separation of functions from processes. A process is a structured set of activities designed to accomplish a defined objective in a measurable and repeatable manner, transforming inputs into outputs. Processes result in a goal-oriented change, and utilize feedback for self-enhancing and self-corrective actions. MOF defines a process as interrelated tasks that, taken together, produce a defined, desired result. A function is an organizational capability, a combination of people, processes (activities), and technology, specialized in fulfilling a specific type of work, and responsible for specific end results. Functions use processes. MOF doesn’t offer a definition for function alone; rather, it defines the term service management function (SMF) as a core part of MOF that provides operational guidance for Microsoft technologies employed in computing environments for information technology applications. SMFs help organizations to achieve mission-critical system reliability, availability, supportability, and manageability of IT solutions.
The interrelationship of people, process, and technology. A widely accepted paradigm for defining the core focus areas in managing organizational improvement is Process - People - Technology (PPT). When using IT Service Management frameworks for organizational improvement, each of these three areas should be addressed. An important consequence of applying this paradigm is the separation of functions from processes. A process is a structured set of activities designed to accomplish a defined objective in a measurable and repeatable manner, transforming inputs into outputs. Processes result in a goal-oriented change, and utilize feedback for self-enhancing and self-corrective actions. MOF defines a process as interrelated tasks that, taken together, produce a defined, desired result. A function is an organizational capability, a combination of people, processes (activities), and technology, specialized in fulfilling a specific type of work, and responsible for specific end results. Functions use processes. MOF doesn’t offer a definition for function alone; rather, it defines the term service management function (SMF) as a core part of MOF that provides operational guidance for Microsoft technologies employed in computing environments for information technology applications. SMFs help organizations to achieve mission-critical system reliability, availability, supportability, and manageability of IT solutions.
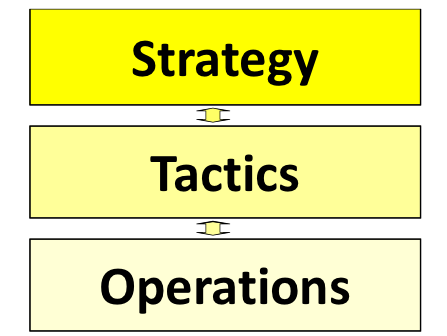 The interrelationship of strategy, tactics, and operations. A important and widely applied approach to the management of organizations is the paradigm of Strategy - Tactics - Operations. The interrelationship of strategy, tactics, and operations A second important and widely applied approach to the management of organizations is the paradigm of Strategy - Tactics - Operations. At a strategic level an organization manages its long-term objectives in terms of identity, value, relations, choices and preconditions. At the tactical level these objectives are translated into specific goals that are directed and controlled. At the operational level these goals are then translated into action plans and realized.
The interrelationship of strategy, tactics, and operations. A important and widely applied approach to the management of organizations is the paradigm of Strategy - Tactics - Operations. The interrelationship of strategy, tactics, and operations A second important and widely applied approach to the management of organizations is the paradigm of Strategy - Tactics - Operations. At a strategic level an organization manages its long-term objectives in terms of identity, value, relations, choices and preconditions. At the tactical level these objectives are translated into specific goals that are directed and controlled. At the operational level these goals are then translated into action plans and realized.
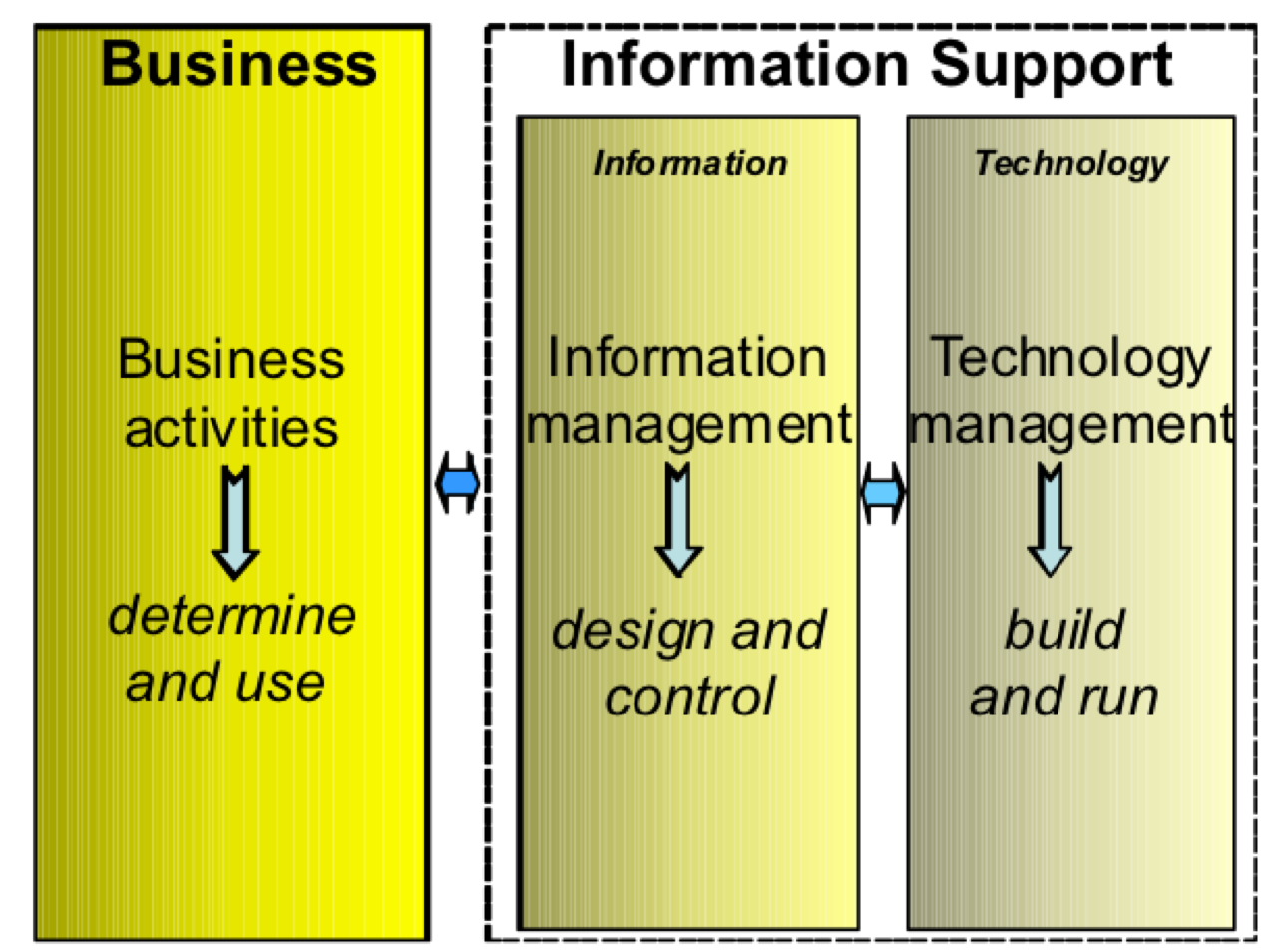 Information processing systems have one and only one goal; to support the primary business processes of the customer organization. Applying the widely accepted control mechanism of Separation of Duties (SoD), also known as Separation of Control (SoC), we find a domain where information system functionality is specified (Information Management), and another domain where these specifications are realized (Technology Management). The output realized by the Technology Management domain is the operational IT service used by the customer in the Business domain.
Information processing systems have one and only one goal; to support the primary business processes of the customer organization. Applying the widely accepted control mechanism of Separation of Duties (SoD), also known as Separation of Control (SoC), we find a domain where information system functionality is specified (Information Management), and another domain where these specifications are realized (Technology Management). The output realized by the Technology Management domain is the operational IT service used by the customer in the Business domain.
The combination of STO and SoD delivers a very practical blueprint of responsibility domains for the management of organizations; the Strategic Alignment Model Enhanced 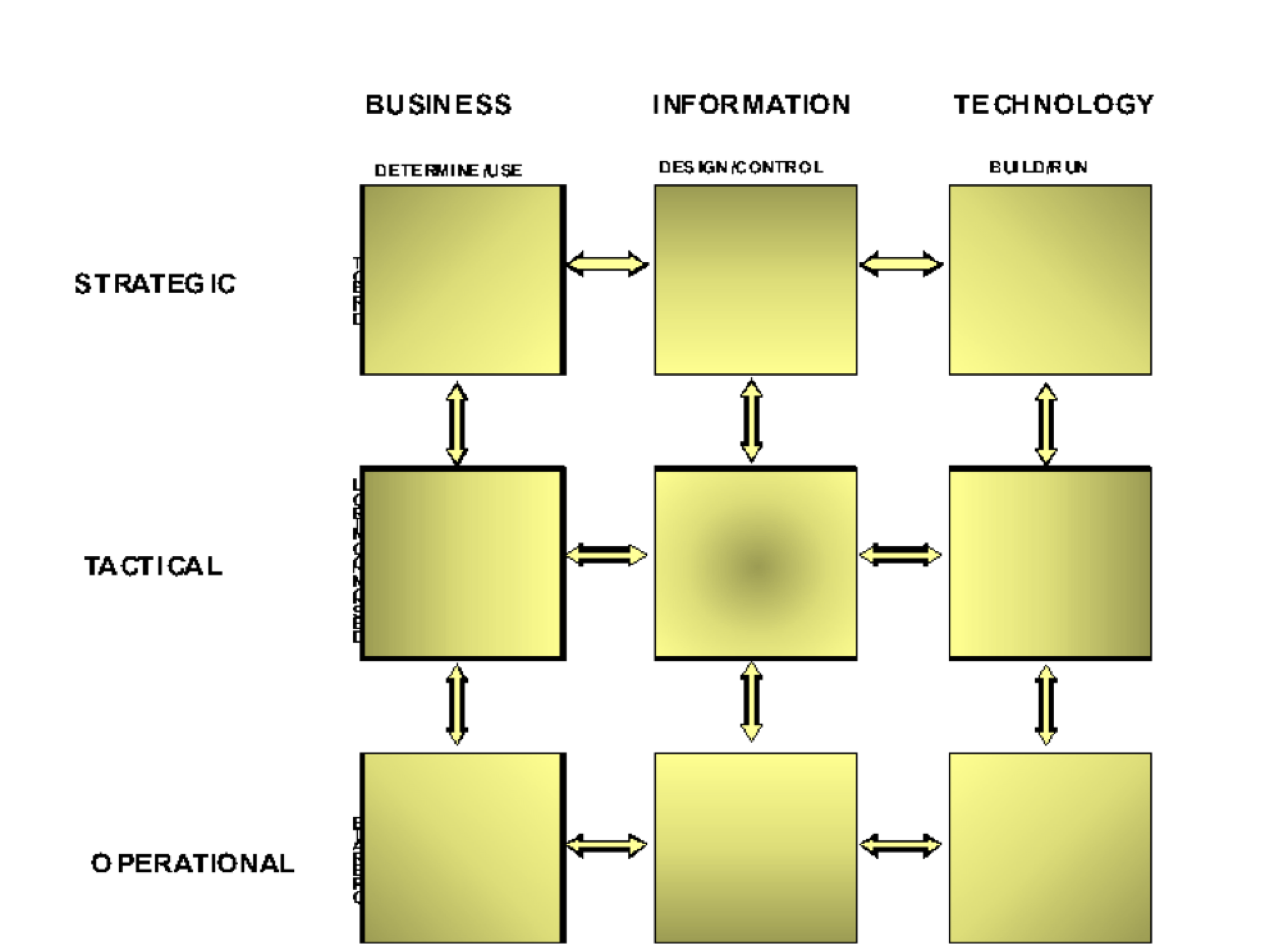 This blueprint provides excellent services in comparing the positions of management frameworks, and in supporting discussions on the allocation of responsibilities—for example, in discussions on outsourcing. It is used by a growing number of universities, consultants and practitioners.
This blueprint provides excellent services in comparing the positions of management frameworks, and in supporting discussions on the allocation of responsibilities—for example, in discussions on outsourcing. It is used by a growing number of universities, consultants and practitioners.
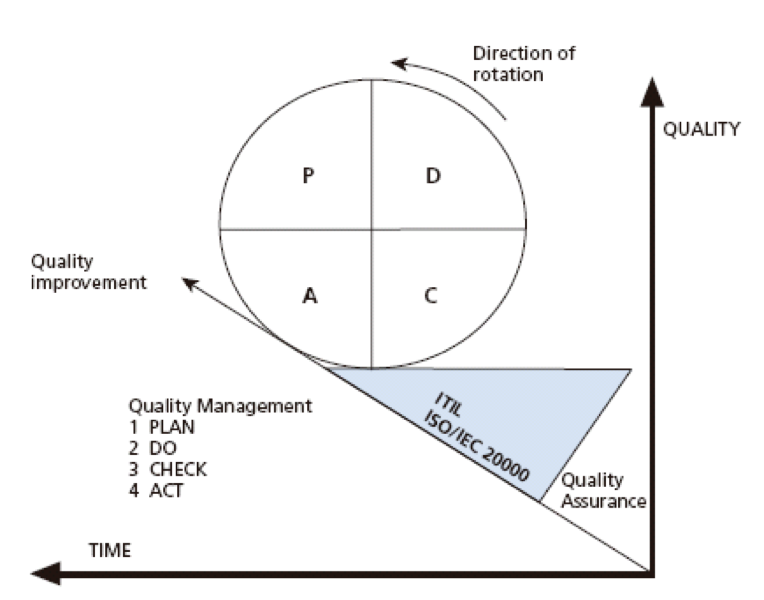 Since IT services are recognized as strategic business assets, organizations need to continually improve the contribution of IT services to business functions, in terms of better results at lower cost. A widely accepted approach to continual improvement is Deming’s Plan-Do-Check-Act Management Cycle.This implies a repeating pattern of improvement efforts with varying levels of intensity. The cycle is often pictured, rolling up a slope of quality improvement, touching it in the order of P-D-C-A, with quality assurance preventing it from rolling back down.
Since IT services are recognized as strategic business assets, organizations need to continually improve the contribution of IT services to business functions, in terms of better results at lower cost. A widely accepted approach to continual improvement is Deming’s Plan-Do-Check-Act Management Cycle.This implies a repeating pattern of improvement efforts with varying levels of intensity. The cycle is often pictured, rolling up a slope of quality improvement, touching it in the order of P-D-C-A, with quality assurance preventing it from rolling back down.
The framework above organizes governance into six areas of focus, which span the entire organization. We describe these areas of focus as Perspectives. Perspectives each encompass distinct responsibilities owned or managed by functionally related stakeholders. There are three perspectives addressing Business Stakeholders and three perspectives addressing Technology Stakeholders Each of the six Perspectives that make up the Cloud Framework as is described below. By clicking on the area’s in the image you can find more detailed information.
Helps stakeholders understand how to update staff skills and organizational processes involved in business support capabilities, to optimize business value with new services adoption.
Common Roles: Human Resources; Staffing; People Managers.
The Business Perspective is focused on ensuring that IT is aligned with business needs and that IT investments can be traced to demonstrable business results. Engage stakeholders within the Business Perspective to create a strong business case for example cloud adoption, prioritize initiatives, and ensure that there is a strong alignment between your organisation business strategies and goals and IT strategies and goals
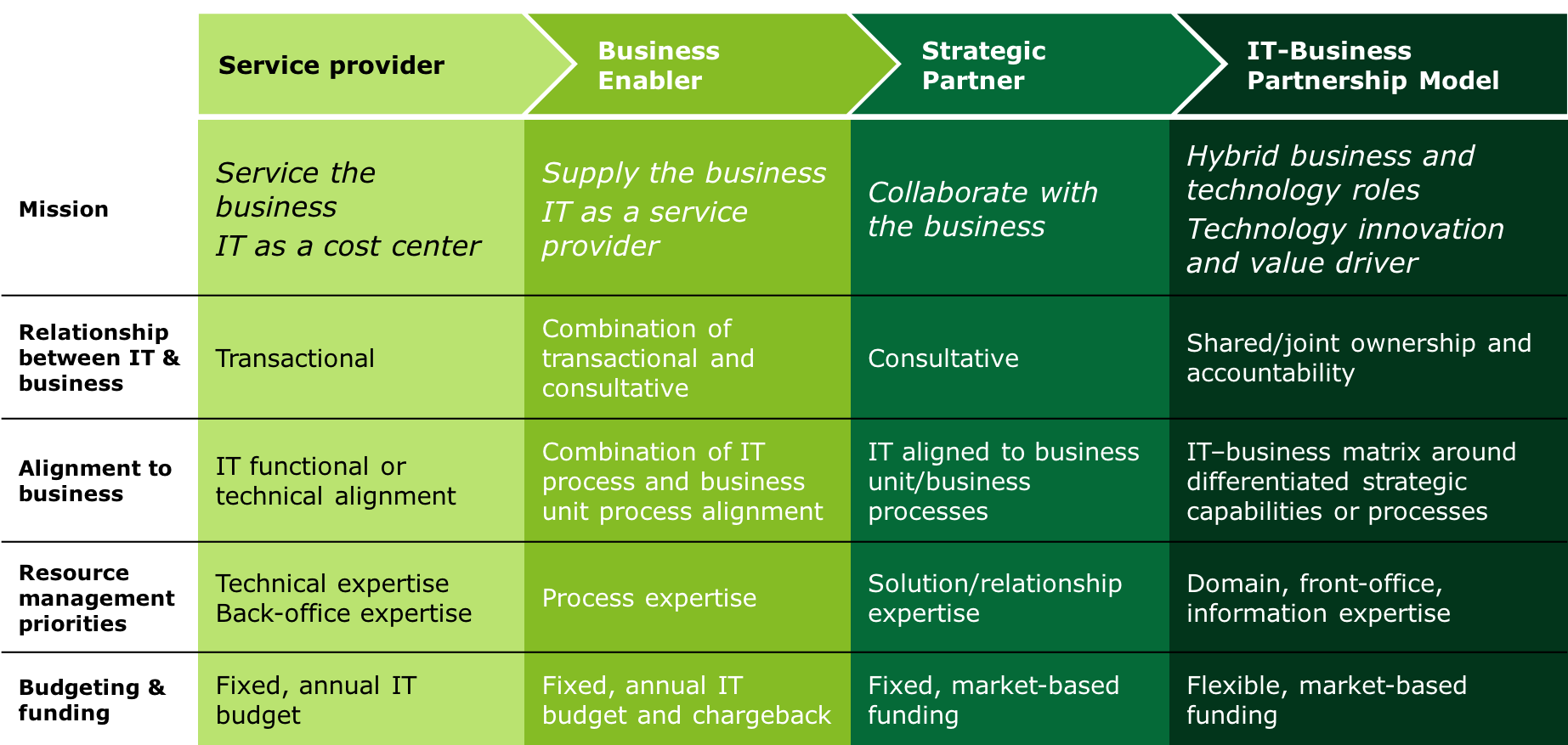
Path to Partnership
You should look critical towards your IT organisation and evaluate what kind of role you would like to play. The image below explains the path to partnership, which most IT organisation strife for.
Addresses the organisation capability to plan, allocate, and manage the budget for IT expenses given changes introduced with a services consumption model. A common budgeting change involves moving from capital asset expenditures and maintenance to consumption-based pricing. The move requires new skills to capture information and new processes to allocate cloud asset costs that accommodate consumption-based pricing models. You want to ensure that your organization maximizes the value of its cloud investments. Charge-back models are another common change with cloud adoption. Cloud services provide options to create very granular charge-back models. You will be able to track consumption with new details, which creates new opportunities to associate costs with results.
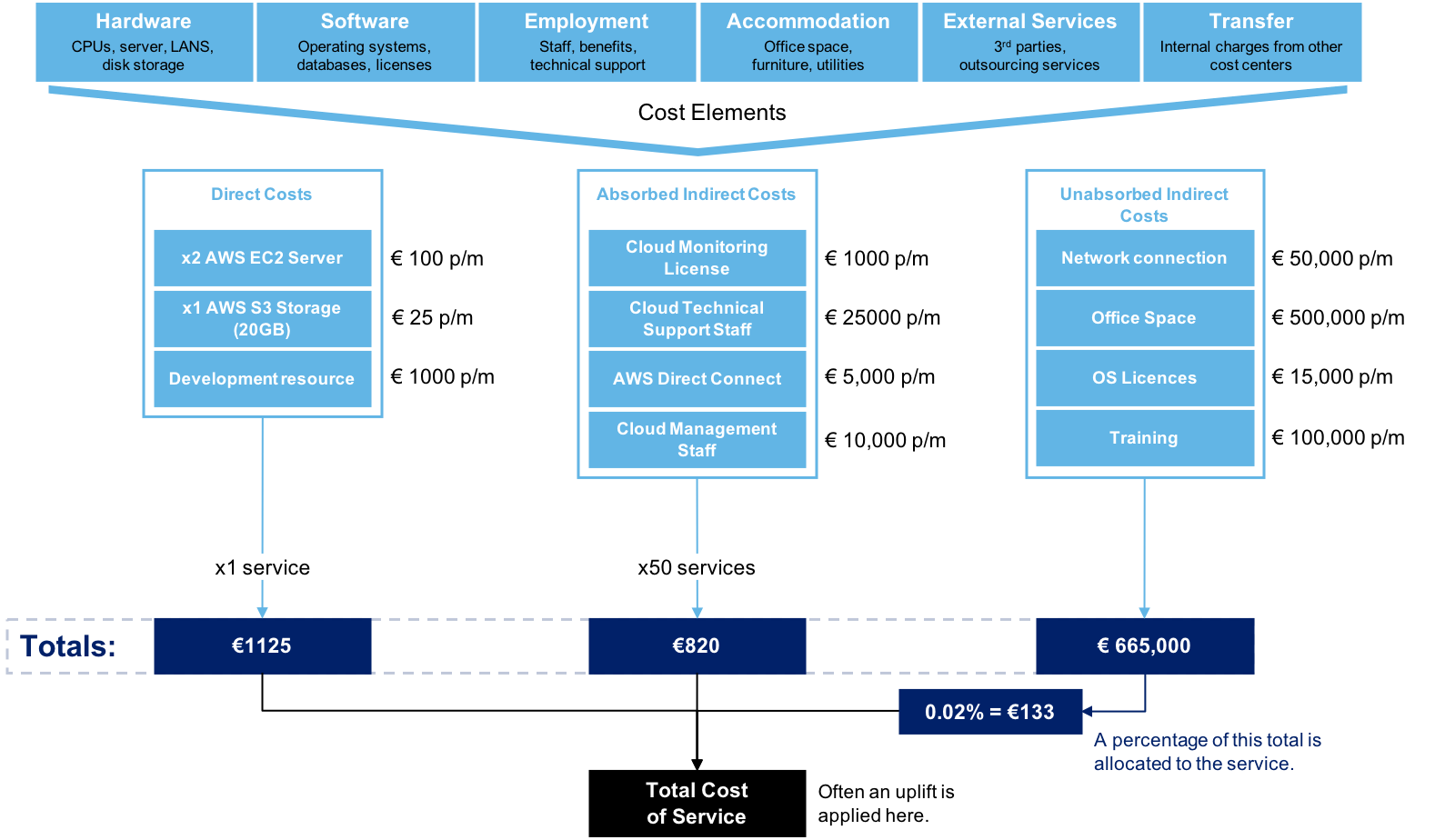
Cost for Services
It can be difficult to calculate the cost of a service. In the picture shows a model to help you make this calculation.
- Direct costs are clearly attributable to a single service
- Absorbed Indirect costs are those incurred on behalf of all or a number of services. These have to be apportioned to all or the number of services in a fair manner.
- Un-absorbed Indirect costs cannot be apportioned to a set of services and have to be recovered from all services in as fair away as is possible
Cost Elements for Agile Teams
When using cloud you probably will introduce agile teams. The advantage of Agile teams is that there cost are predictable. 
Cost Control for Agile Teams
As stated the one of the advantages of Agile Teams is cost control, the burn rate is stable so if you get a stable income the finacial out come is predicatable. Let’s take a look at an example using a battery cost model.
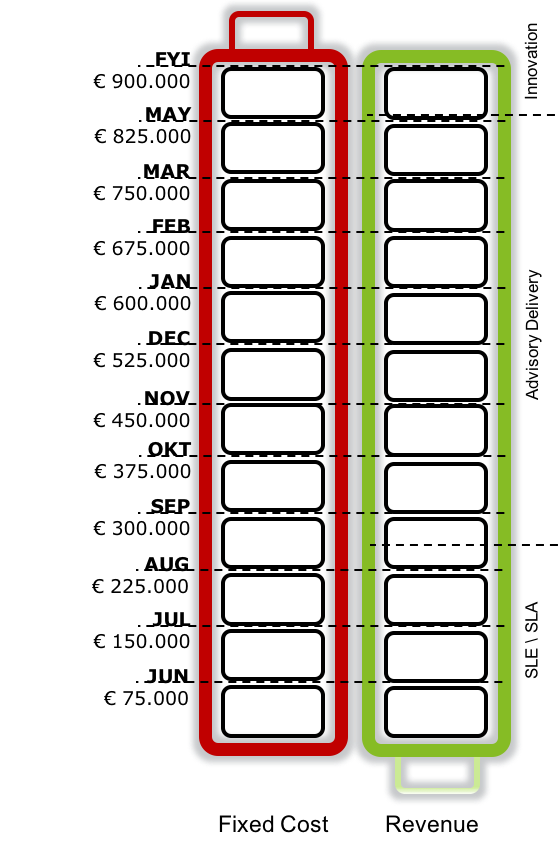
An agile team consist of 6 team members. The members have all the same rate (€70 incl. 8% innovation + overhead) as a result the average month cost are €75.000. The total year cost will be €900.000 and therefore the team can spend €72.000 on innovation (4 weeks).
If we take the assumption that the agile team in average will spend 32% of there time on operations in form of SLE/SLA (€288.000) their target is to spend 60% on Advisory and Delivery (€540.000)
Using a battery model we can evaluate if the agile team will break even at the end of FYI.
Compute resources are always charged directly to the functions and therefor don’t need to be part of the battery model
IT services provide efficiencies that reduce the need to maintain applications, enabling IT to focus on business alignment.
 This alignment requires new skills and both new and selectively modified processes between IT and other business and operational areas. IT may need new skills to gather business requirements and new processes to solve business challenges. The business has increasing requirements on IT, to be faster and flexible when delivering solutions which needs to be 100% available and supported 7x24x365. There is a need for utility based cost model with full transparency and cost insight up-front. IT should be able to support them with Technology advice and implementation support. Predefined “checked-boxed” self-service approach is expected for standard services like: Security, Data & Service Integration, Technology Preference, Certification demands and Operations as a Service.
This alignment requires new skills and both new and selectively modified processes between IT and other business and operational areas. IT may need new skills to gather business requirements and new processes to solve business challenges. The business has increasing requirements on IT, to be faster and flexible when delivering solutions which needs to be 100% available and supported 7x24x365. There is a need for utility based cost model with full transparency and cost insight up-front. IT should be able to support them with Technology advice and implementation support. Predefined “checked-boxed” self-service approach is expected for standard services like: Security, Data & Service Integration, Technology Preference, Certification demands and Operations as a Service.
The strategy is to deliver a clear and concise agile process for IT services supported by Multi Vendor Cloud Technology. The experience of consuming cloud services for the business will be identical / seamless through the usage of a predefined check-boxed Cloud Portal. By working together as one agile team we will deliver business value by shortening development time, increasing productivity and increasing capacity. Determined for 100% availability, reliability and secured by design increasing our effectiveness in delivering cloud services to our partners and practitioners.
Agility and Speed
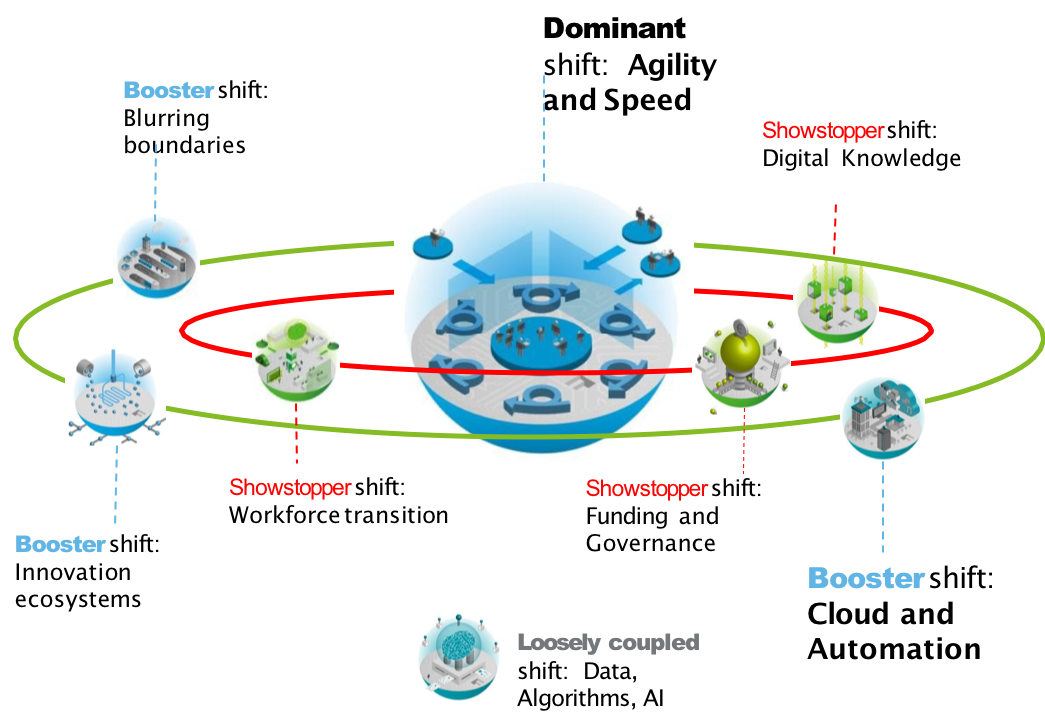
A major shift within IT is the demand for Agility and Speed which is stimulated with cloud services becoming general available by credit card.
Strategy Contributions
- Increase Agility and Speed by setting up a Agile team
- Support the shift towards Cloud and Automation
Pre-requisites to make IT successful
- Accelerate Workforce transition by adding jobs with new skills
- Increase Digital knowledge / DNA by providing training and adjusting the organisational IT culture and environment
- Adjust funding and governance by transforming to digital leadership/governance, culture of innovation and funding model adjustments
IT as Cloud Provider and Broker

Cloud Consumer
The cloud consumer is the ultimate stakeholder that the cloud computing service is created to support. A cloud consumer represents a person or organization that maintains a business relationship with, and uses the service from, a cloud provider. A cloud consumer browses the service catalog from a cloud provider, requests the appropriate service, sets up service contracts with the cloud provider, and uses the service. The cloud consumer may be billed for the service provisioned, and needs to arrange payments accordingly.
Cloud Provider
A cloud provider can be a person, an organization, or an entity responsible for making a service available to cloud consumers. A cloud provider builds the requested software/platform/ infrastructure services, manages the technical infrastructure required for providing the services, provisions the services at agreed-upon service levels, and protects the security and privacy of the services. Cloud providers undertake different tasks for the provisioning of the various service models
Cloud Broker
As cloud computing evolves, the integration of cloud services can be too complex for cloud consumers to manage. A cloud consumer may request cloud services from a cloud broker, instead of contacting a cloud provider directly. A cloud broker is an entity that manages the use, performance, and delivery of cloud services and negotiates relationships between cloud providers and cloud consumers.
In general, a cloud broker can provide services in three categories:
- Service Intermediation: A cloud broker enhances a given service by improving some specific capability and providing value-added services to cloud consumers. The improvement can be managing access to cloud services, identity management, performance reporting, enhanced security, etc.
- Service Aggregation: A cloud broker combines and integrates multiple services into one or more new services. The broker provides data integration and ensures the secure data movement between the cloud consumer and multiple cloud providers.
- Service Arbitrage: Service arbitrage is similar to service aggregation except that the services being aggregated are not fixed. Service arbitrage means a broker has the flexibility to choose services from multiple agencies. The cloud broker, for example, can use a credit-scoring service to measure and select an agency with the best score
Encompasses your organisation capability to measure the benefits received from their IT investments. For many organizations, this represents Total Cost of Ownership (TCO) or Return on Investment (ROI) calculations coupled with budget management.
Focuses on the organization capability to understand the business impact of preventable, strategic, and external risks to the organisation. For many, these risks stem from the impact of financial and technology constraints on agility. Organizations find that with a move to the cloud, many of these constraints are reduced or eliminated. Taking full advantage of this newfound agility requires teams to develop new skills to understand the competitive marketplace and potential disrupter, and to explore new processes for evaluating the business risks of such competitors.
Information security has long been built on the assumption that the internal network within a company is a safe area and has to be protected against threats from outside. In the digitalized world where everything is interconnected, the traditional company boundaries are more complex and therefore, information security has to be redefined accordingly.
Information security in the modern business world can be defined in the following three categories:
- Devices should contain as little confidential data as possible because they are prone to be lost, stolen or misused. All terminal devices should be protected by an intrusion prevention software, and all data in the devices should be encrypted. These actions can be thought as “vaccinations” against various threats i.e., not giving 100% protection but a good enough precaution that can stop the viruses spreading even further.
- Networks where the devices are used vary from completely open to closed networks. Most companies’ internal networks may still be insecure even when protected. Therefore, the traffic in the networks must be controlled and analysed to detect the anomalies as early as possible so that the possible damages can be stopped or minimized. Network protection needs both preventive and recovery actions coupled with the ability to react fast and professionally against any security hazard.
- Information storages containing the company information should be protected according to criticality of the information. All information should be classified, yet aiming for simplicity. For example, classifying the information as highly confidential, company confidential or public. This way the protection can be defined separately for each class, and the highest, and usually the most expensive protection mechanisms can be applied where it is truly needed while keeping the protection to fit-for-purpose level in the other levels.
On top of technical information security, a well-designed Identity and Access Management (IAM) is needed in order to prevent misuse of a (legitimate) identity that can lead to:
- grant access to confidential information to unwanted parties
- copy and use of the information for unauthorized/illicit purposes
- destroy the data or cause other harm to it
- modify the data to suit for own purposes
One of the most important security measures is to minimize the possibility of human errors that can pave the way for security violations. The following actions should be considered for prevention:
- Instructing and tutoring the users to prevent exposure for security threats caused by careless use. All users should be instructed to use safe passwords and safe storing of passwords as well as what to do if the terminal device is lost or they suspect a security violation to take place. These action are aimed to prevent the identity thefts.
- Appropriate definition of user rights to prevent unauthorized access or possibility to perform actions that exceed the access rights. For example, an employee should not have the rights to both create and approve the same chargeable invoice. These measures are aimed to prevent the misuse of an identity.
Information security is conducted in co-operation between the following three parties:
- Chief Information Security Officer (CISO) is responsible for planning and execution of the information security
- Business Management is responsible for ensuring the business continuity and approving of the acceptable risk levels
- Service Providers are responsible for information security operations
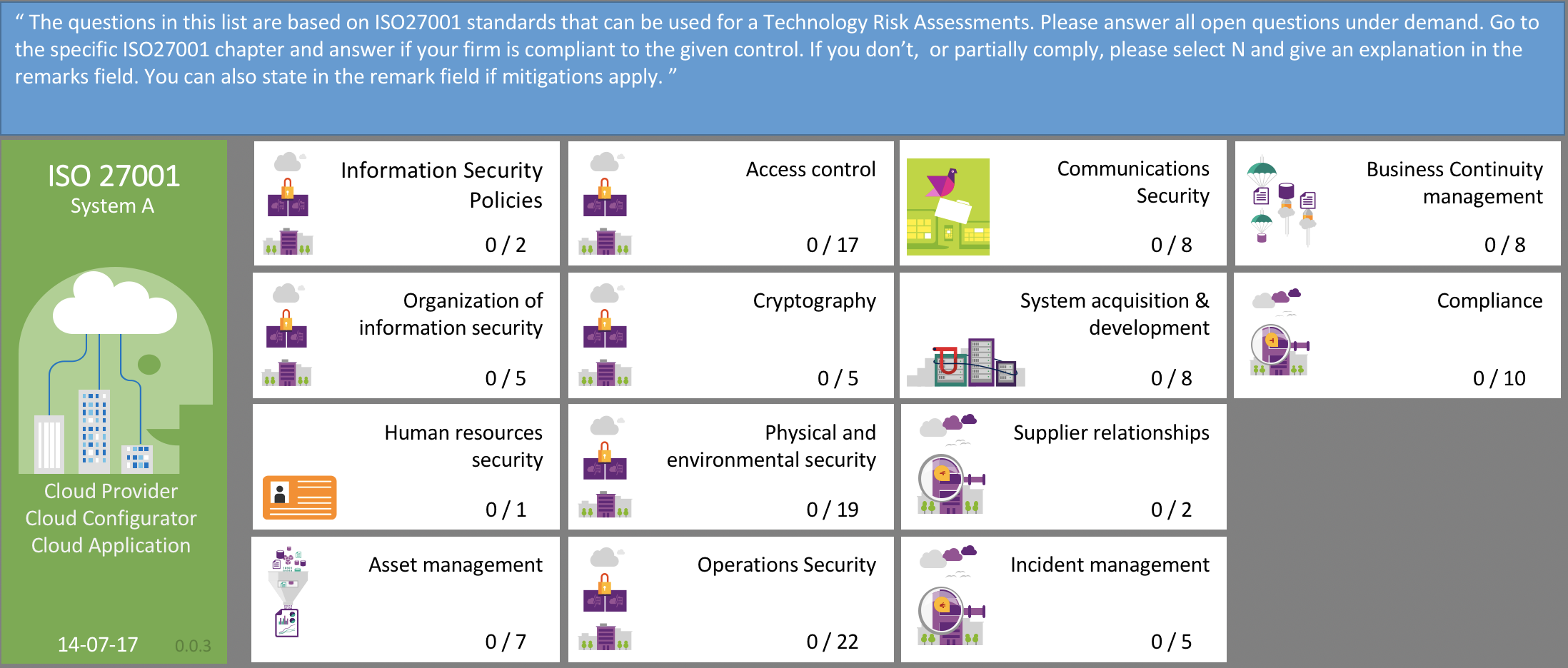
IT-related risk management must also be an integrated part of the companies overall management systems. Risk management means systematically recognizing and preparing for factors that cause uncertainty and threats to company objectives and operations. Since risks can never be entirely eliminated, management must define the companies acceptable risk level. Company management defines risk management policies, applicable methods, responsibilities and tasks for different parties as well as practices for monitoring and reporting. Business targets and uncertainty factors change over time, so risk management must also be treated as a continuous process. Below is the image of an excel you can use to make a ISO27001 based risk assessment, just click on it to open it.
Quality assurance keeps IT operations in line with standards and best practices, and ensures that the quality requirements of IT are met. IT processes must be described and they must aim to produce the best user experience. Quality assurance needs to be integrated into all IT processes and services. Quality assurance is not only about the systematic measurement of operations, processes, and services, but also their continuous development and overall business performance assurance. Additionally, it means maintaining constant focus on the business value created by IT.
Provides guidance for stakeholders responsible for talent development, training, and communications. Helps stakeholders understand how to update staff skills and organisational processes with cloud based competencies.
Common Roles: Business Managers; Finance Managers; Budget Owners; Strategy Stakeholders.
The Talent perspective covers organisational staff capability and change management functions required for efficient cloud adoption. Engage stakeholders within the People Perspective to evaluate organizational structures and roles, new skill and process requirements, and identify gaps. Performing an analysis of needs and gaps helps you to prioritize training, staffing, and organizational changes so that you can build an agile organization that is ready for effective cloud adoption. It also helps leadership communicate changes to the organization. The People Perspective supports development of an organization-wide change management strategy for successful cloud adoption
Addresses the organisation capability to project personnel needs and to attract and hire the talent necessary to support the organisations goals. Service adoption requires that the staffing teams in your organization acquire new skills and processes to ensure that they can forecast and staff based on your organizations needs. These teams need to develop the skills necessary to understand cloud technologies, and they may need to update processes for forecasting future staffing requirements.
When building you teams have a look at the role descriptions we made.
Addresses the organization capability to ensure employees have the knowledge and skills necessary to perform their roles and comply with organisational policies and requirements. Staff in your organization will need to frequently update the knowledge and skills required to implement and maintain cloud services. Training modalities may need to be revised so that the organization can embrace the speed of change and innovation. Trainers will need to develop new skills in training modalities and new processes for dealing with rapid change.
Focuses on the organisation capability to manage the effects and impacts of business, structural, and cultural change introduced with cloud adoption. Change management is central to successful cloud adoption. Clear communications, as always, are critical to ease change and reduce uncertainty that may be present for staff when introducing new ways of working. As a natural part of cloud adoption, teams will need to develop skills and processes to manage ongoing change.
Addresses our capability to ensure workers receive competitive compensation and benefits for what they bring,
Focuses on our capability to ensure the personal fulfilment of employees, their career opportunities and their financial security.
Provides guidance to stakeholders who support business processes with technology, and who are responsible for managing and measuring the resulting business outcomes. Helps stakeholders understand how to update staff skills and organizational processes necessary to ensure business governance in the cloud.
Common Roles: CIO; Program Managers; Project Managers; Enterprise Architects; Business Analysts; Portfolio Managers.
The Governance Perspective focuses on the skills and processes that are needed to align IT strategy and goals with your organisation business strategy and goals, to ensure your organization maximizes the business value of its IT investment and minimizes the business risks. This Perspective includes Program Management and Project Management capabilities that support governance processes for service adoption and ongoing operations.
Service Life Cycle
The overall service life cycle can be divided into 4 clear steps;
- Demand: ensure that the service requests of the business have an owner, are clearly defined, prioritized and approved
- Deliver: creates the services defined by the business, according to delivery method
- Operate: ensures that the services are operated within the agreed service level
- Retire: ensures the correct disposal of the services which are no longer required.
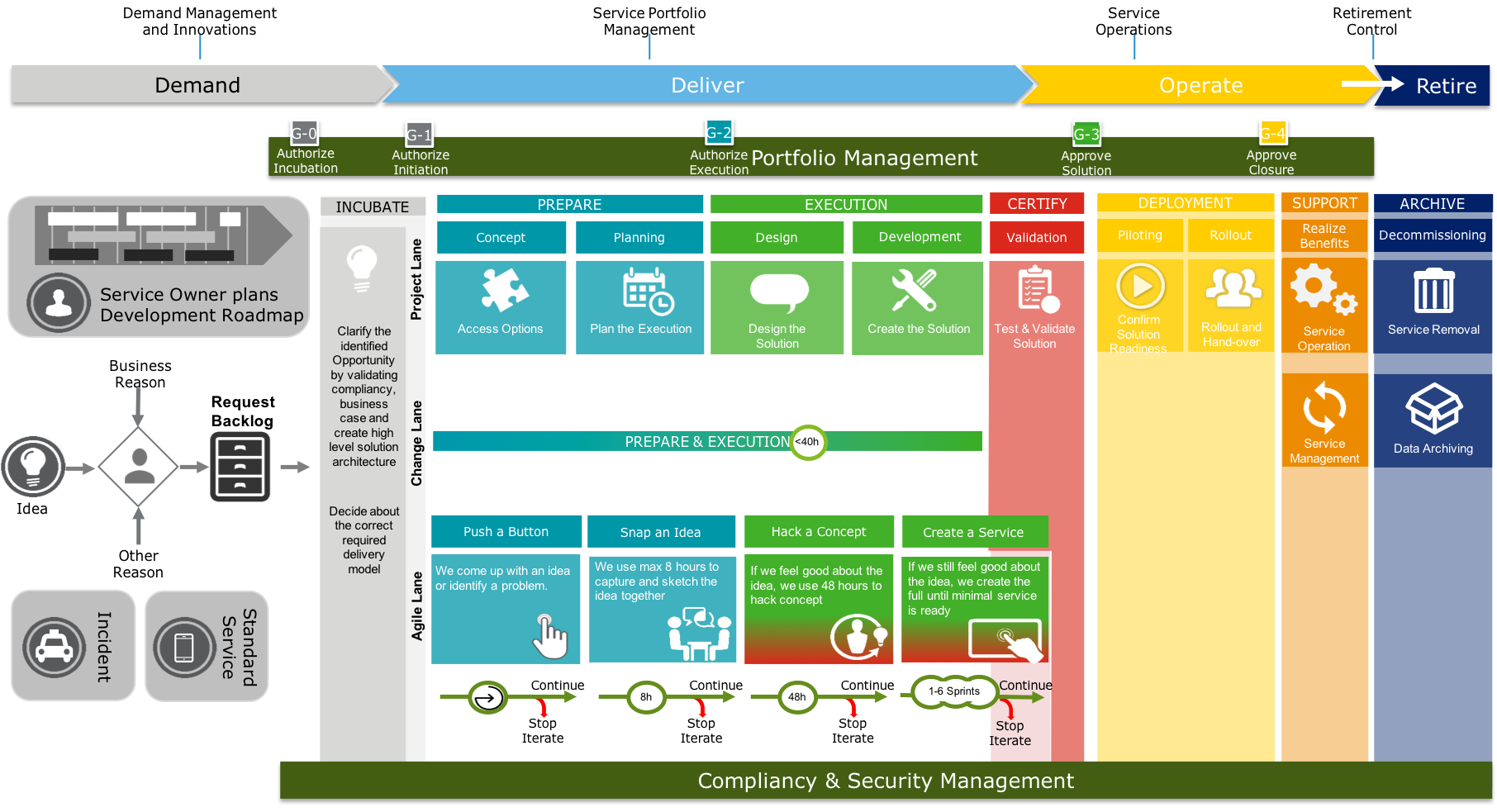
The Service Life Cycle start with the creation of a Service Plan by the Business Owner. When the business demands on the service are clear, a product request can be created. This request is validate and approved (G-0) by the CTO responsible for the business function. During the incubation phase a high level solution direction and cost estimation is made. This information is added to the product request. This request is again validated and approved (G-1) by the responsible CTO. After this approval the delivery is planned according to the selected delivery lane. When the requested service needs goods or external services then CTO is approval (G-2) is required before building of the services can start. During the certification phase, the mandatory tests are evaluate and only when successful or after exception sign-off of the CTO (G-3) the service will be deployed. After the last deployment for this service, the product request will be closed (G-4)
Service Demand
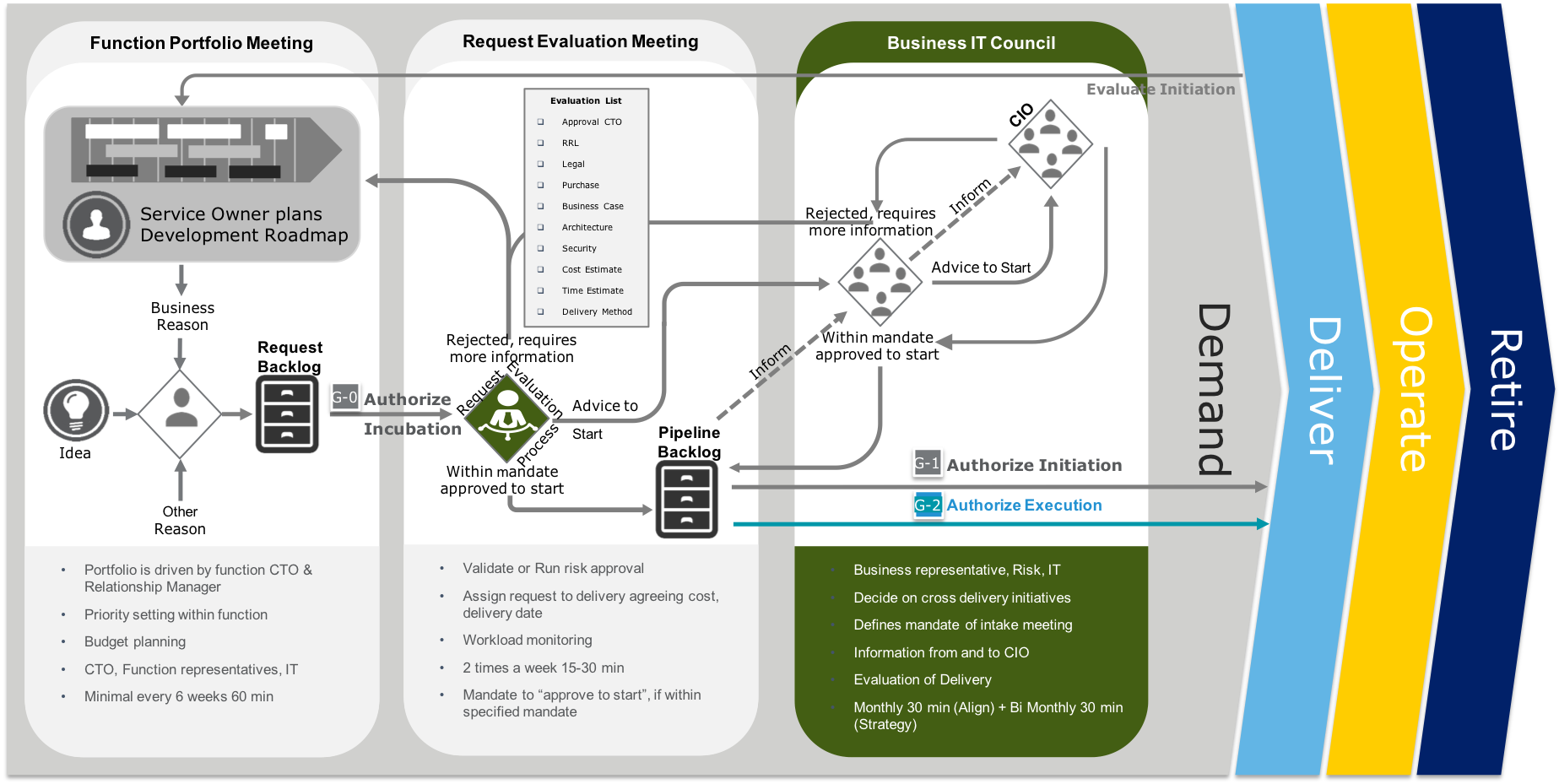
For every function group there will be regular portfolio meeting, where business and the alignment manager meet together defining which services are required by the business. For each service the CTO decides if IT should invert time creating a high level solution direction. During this incubation phase also all external, risk and compliancy task will be performed. When services has impact on more then one function group the proposal needs to evaluated by the Business IT council. If the cost of the services is above the mandate of the Business IT council it will be forwarded to the CIO for approval. After the product request has been updated with the required approval the CTO has to give his final approval.
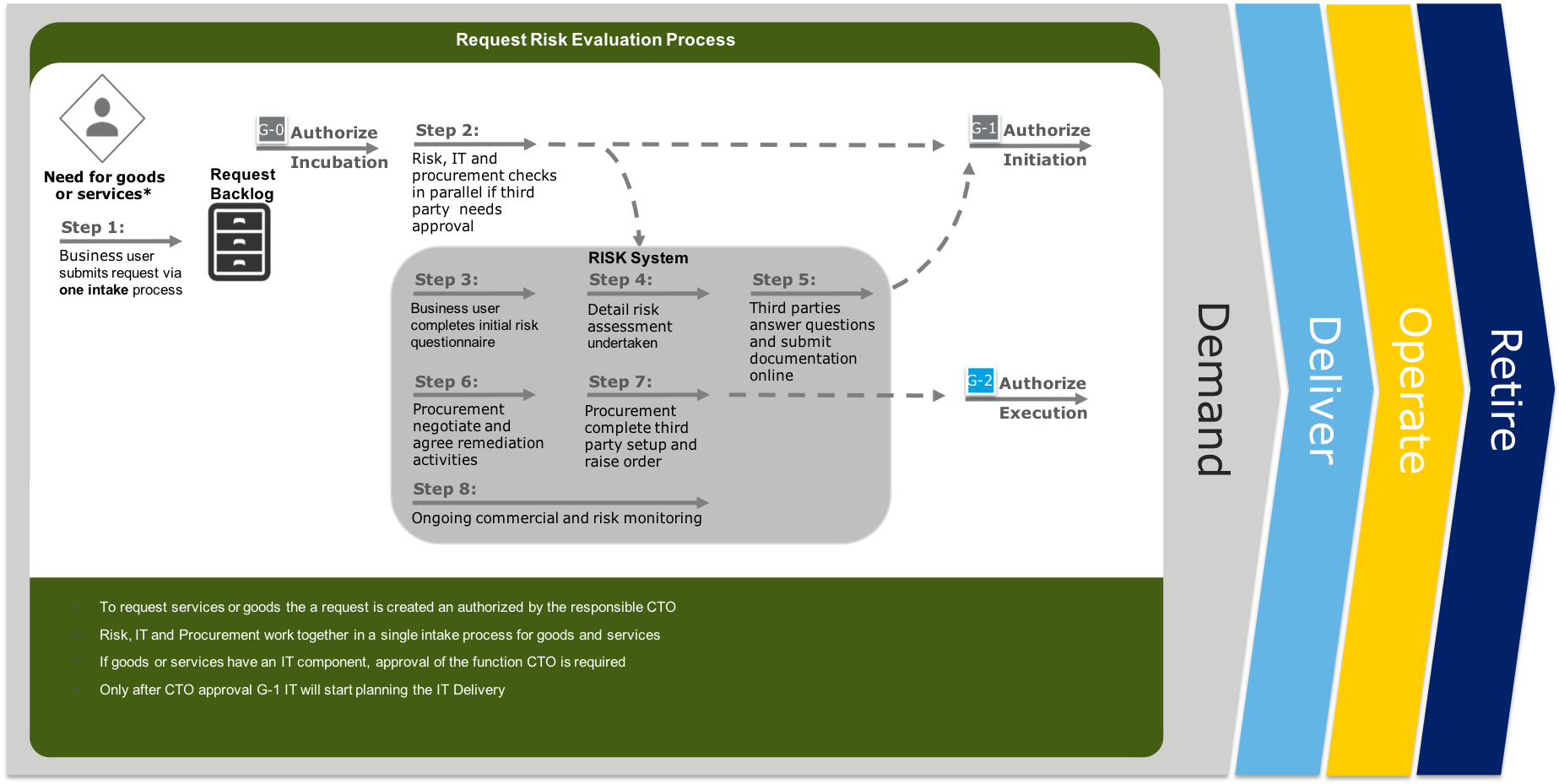
When goods or external services are required an additional Risk and compliancy check needs to be done. Any purchasing activity needs to be completed (step 7) before (G-2)
Service Delivery
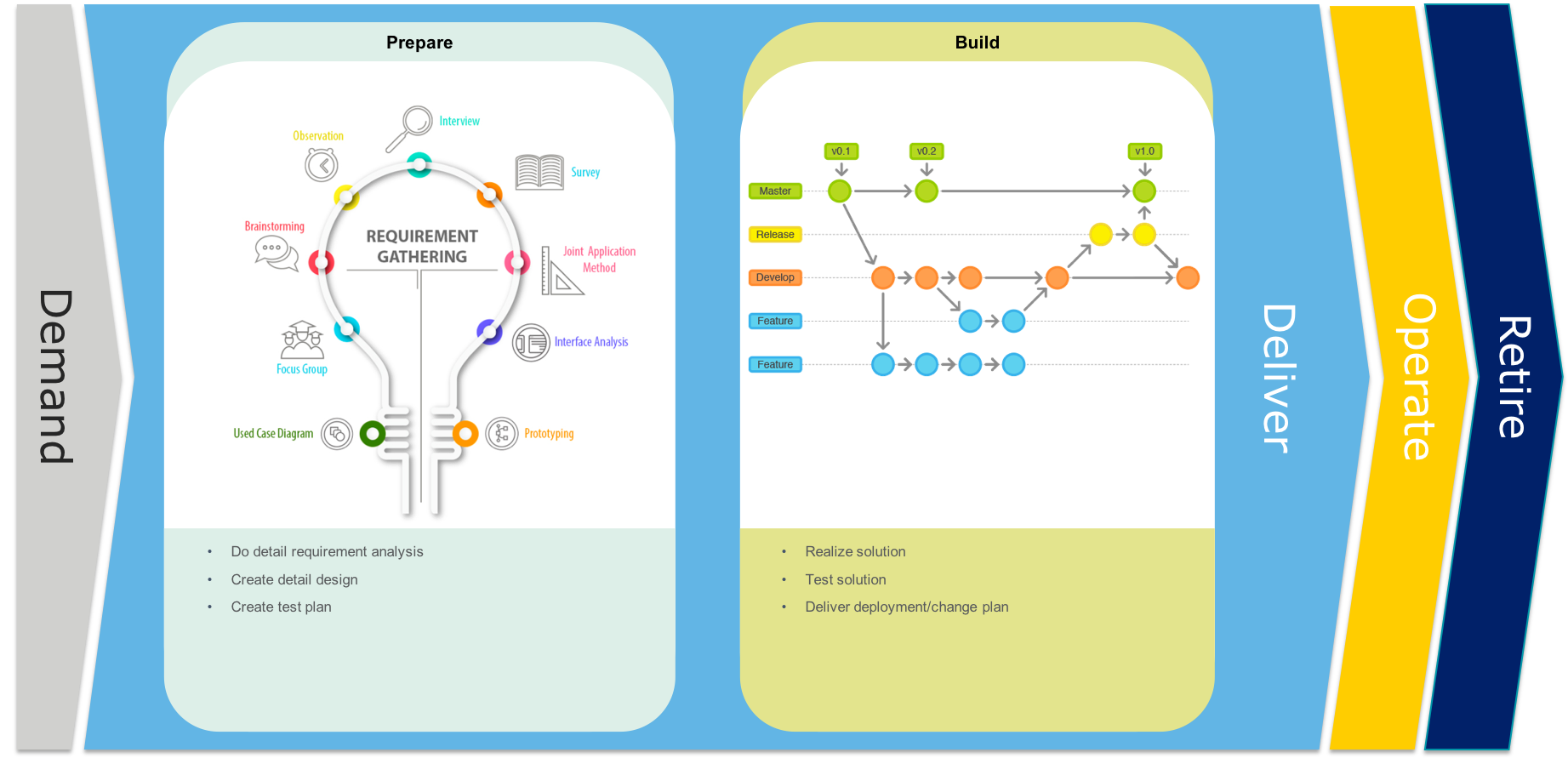
When for a services an traditional delivery model is chosen then during the preparation phase we will focus on requirements gathering and detail design. During the Build phase we will build one or more features and combine them later into on release.
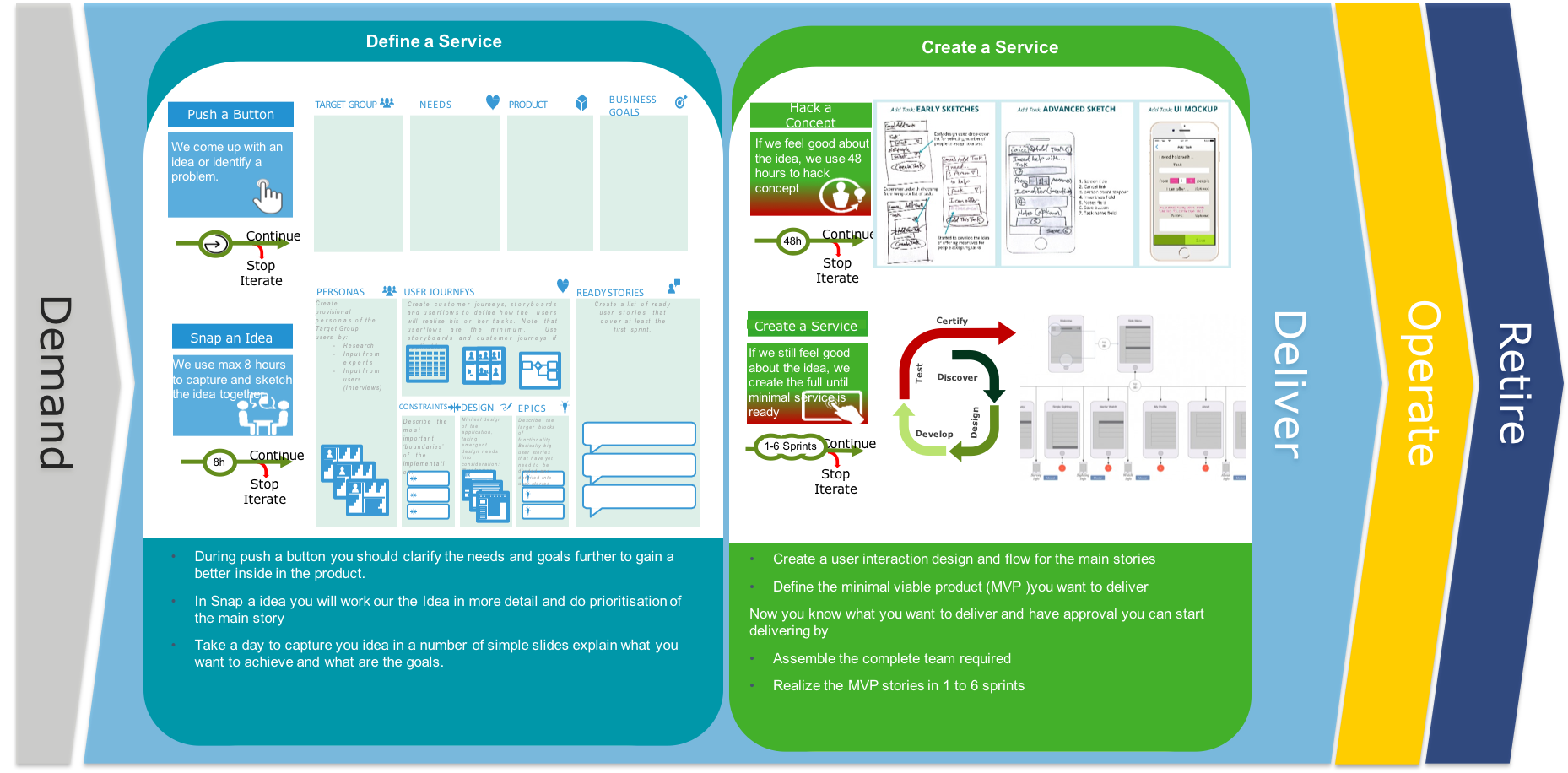
User Stories: In consultation with the customer or product owner, the team divides up the work to be done into functional increments called “user stories.” Each user story is expected to yield a contribution to the value of the overall product.
Daily Meeting: Each day at the same time, the team meets so as to bring everyone up to date on the information that is vital for coordination: each team members briefly describes any “completed” contributions and any obstacles that stand in their way.
Incremental Development: Nearly all Agile teams favor an incremental development strategy; in an Agile context, this means that each successive version of the product is usable, and each builds upon the previous version by adding user-visible functionality.
Iterative Development: Agile projects are iterative insofar as they intentionally allow for “repeating” software development activities, and for potentially “revisiting” the same work products.
Team: A “team” in the Agile sense is a small group of people, assigned to the same project or effort, nearly all of them on a full-time basis. A small minority of team members may be part-time contributors, or may have competing responsibilities.
Milestone Retrospective: Once a project has been underway for some time, or at the end of the project, all of the team’s permanent members (not just the developers) invests from one to three days in a detailed analysis of the project’s significant events.
Personas: When the project calls for it - for instance when user experience is a major factor in project outcomes - the team crafts detailed, synthetic biographies of fictitious users of the future product: these are called “personas”.
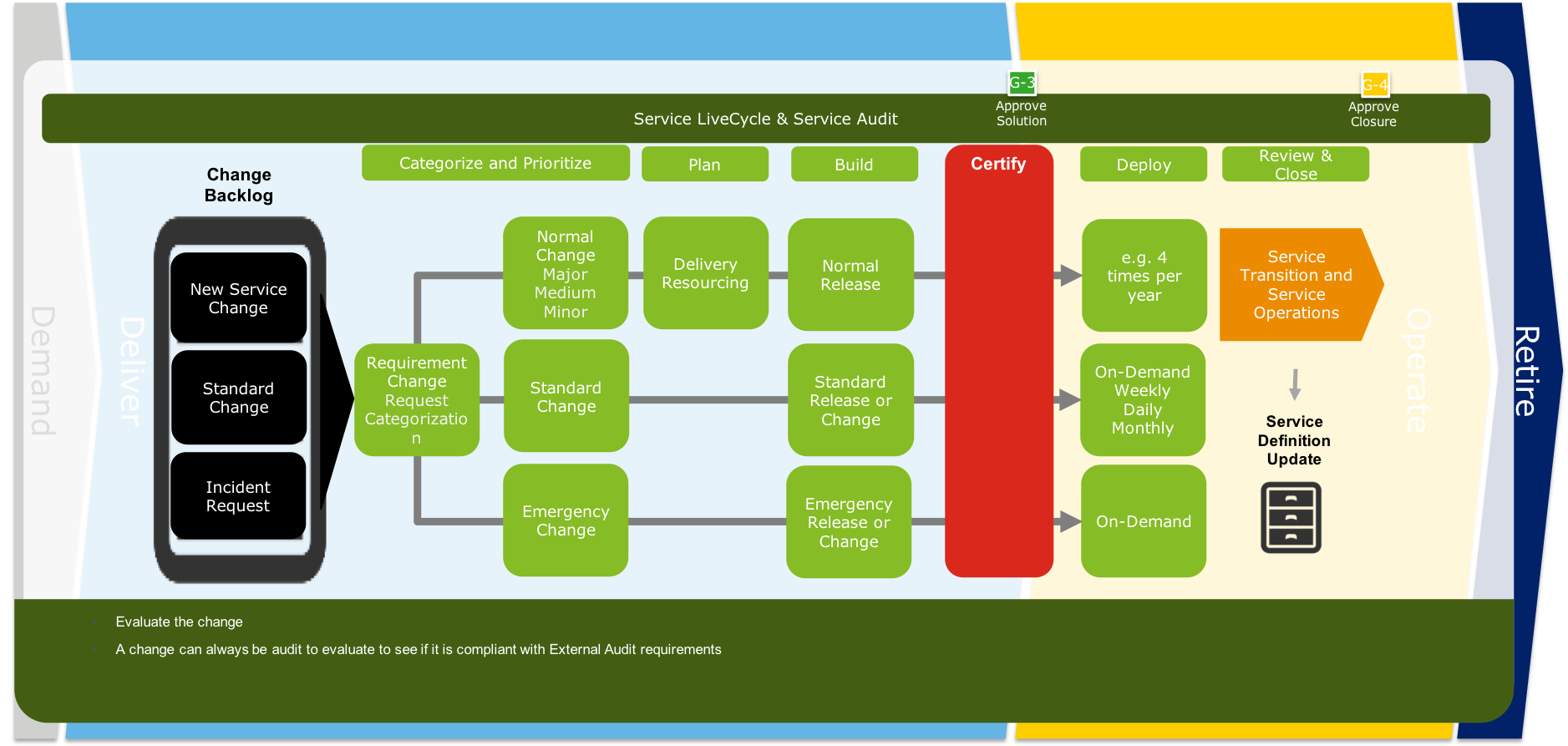
Within the change process we focus on developing standard (preferred automated) service release process. We validate if all required documentation and test are provided. In case of a failure you should perform a root cause analysis and adopt require changes to the standard release process. The task of the changes manager will become more a facilitator of the process and auditor after the changes is completed.(more..)
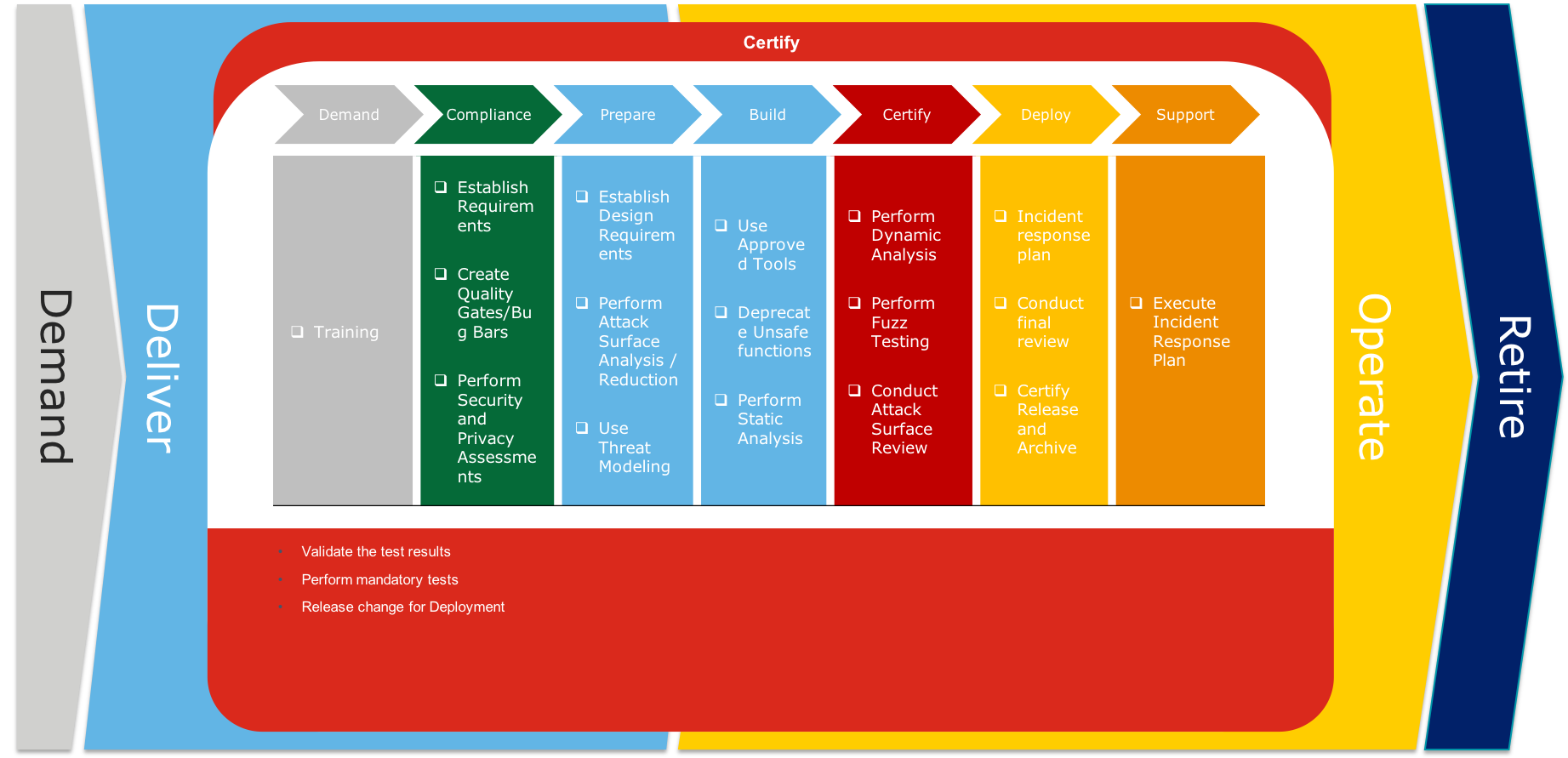
During certify we check if all required certifications steps are performed and completed successful. When not successful and it is required to continue an exception has to be provided by the CTO.
Service Operation
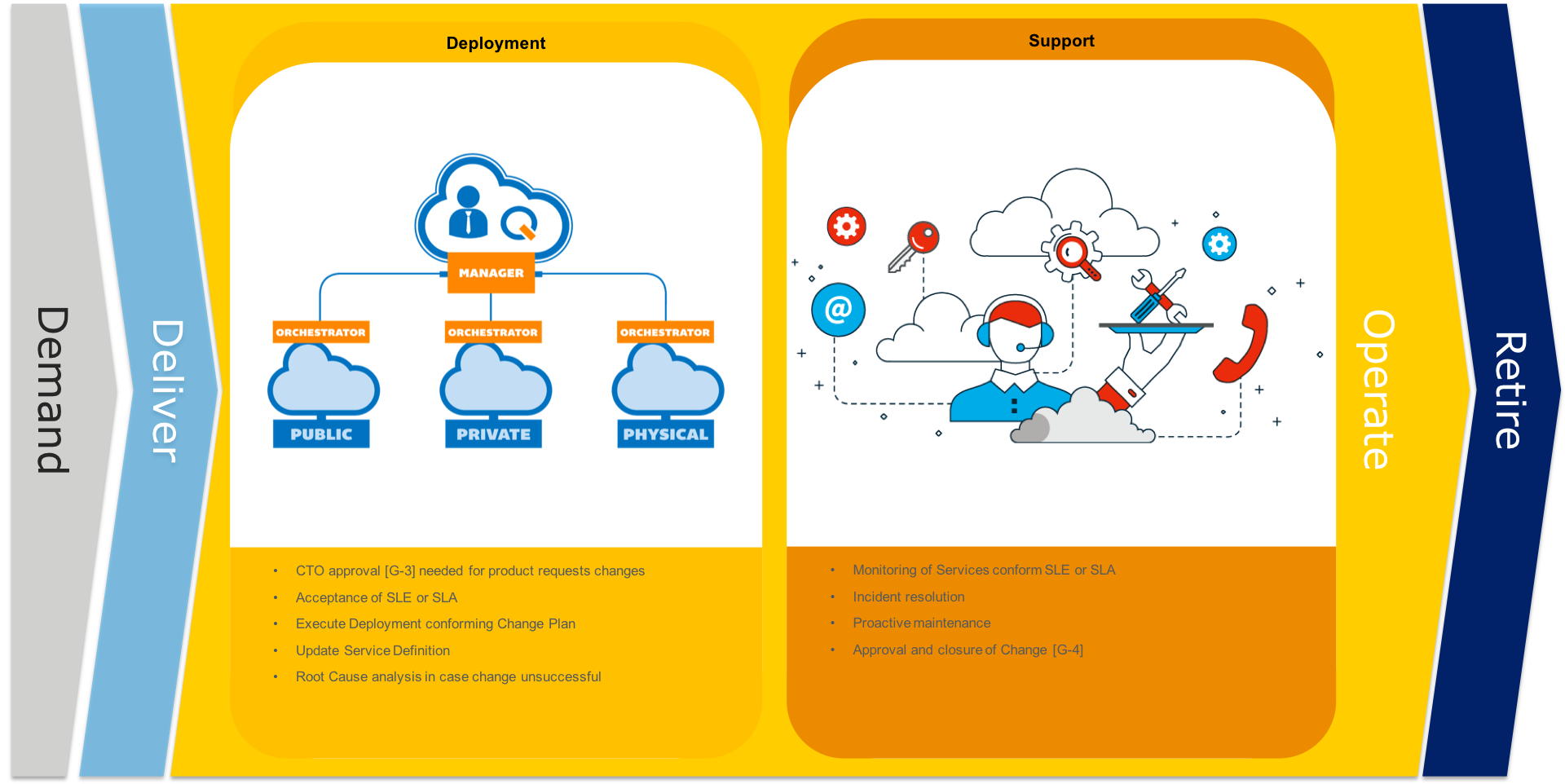
During the deploy phase the provides is preferable automatically deployed on the required infrastructure. The information to support the new/update services is communicated or trained to all impacted resources.
Service Retirement
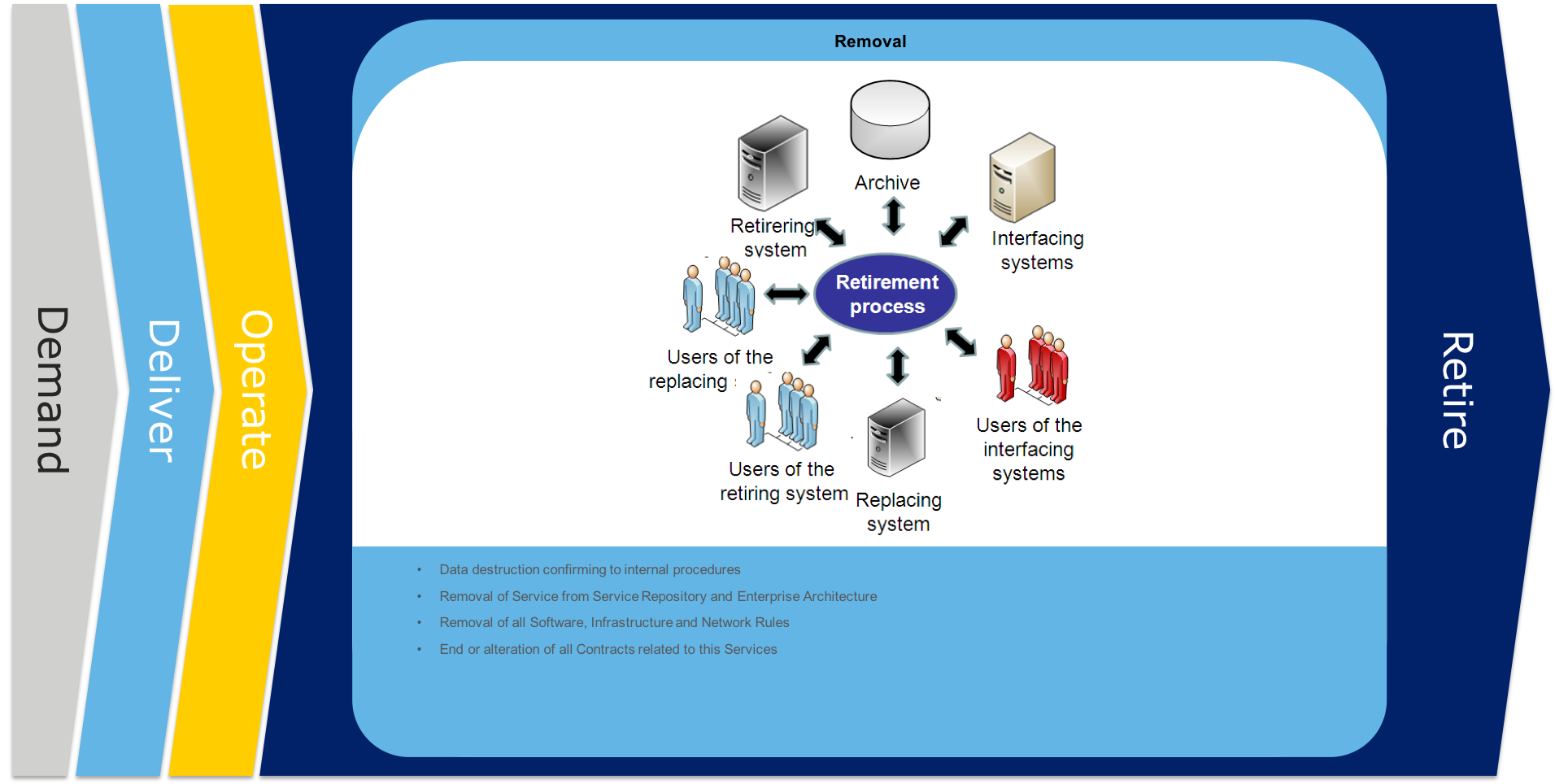
When a service needs to be retired, all data should be archived or destroyed, people should be transferred to other jobs or let go. The services and assets should unregistered.
Focuses on your organisation capability to manage and prioritize IT investments, programs, and projects in alignment with your organisations business goals. Portfolio Management is an important mechanism for determining eligibility for workloads and for prioritizing services delivery. It serves as a focal point for life cycle management of both applications and services. Teams will need to develop new skills and processes to evaluate services and a workloads eligibility.
Development is coordinated by the Development Management Office (DMO), which also sets and promotes development practices for company-wide control, visibility and consistency. DMO has the mandate to classify and prioritize development initiatives to be approved or rejected by Development Portfolio Steering. DMO has control over resources, dependencies and the performance of major development initiatives, while providing the required support and consultation to maximize business benefits creation and minimize risks.
Many organizations have a Project Management Office (PMO) that handles all the same tasks as the DMO, but just for projects. As more and more development takes place beyond projects, it is recommended to have a full-scope DMO to replace the PMO.
Projects vary greatly in terms of targets, duration, budget, staffing and difficulty. Consequently, not all development initiatives require a project and they can be classified as a change. In all development, excluding a straightforward change, the following topics need to be managed:
Business Case validity Goals, scope and constraints Timetables and costs Tasks and deliverables Workloads and needed resources (internal and/or external) Compliance with Enterprise Architecture Quality and risks
Addresses the organisation capability to manage one or several related projects to improve organisational performance and complete the projects on time and on budget. Traditional waterfall methods of program and project management typically fail to keep up with the pace of iterative changes necessary for cloud adoption and operations. Program and Project Managers need to update their skills and processes to take advantage of the agility and cost management features of cloud services. Teams need to develop new skills in agile project management and new processes for managing agile-style projects
Addresses the organisation capability to measure and optimize processes in support of your organisation goals. Services offer the potential for organizations to rapidly experiment with new means of process automation and optimization. Leveraging this potential requires new skills and processes to define Key PerformanceIndicators (KPIs) and create processes to ensure consumption is mapped to business outcomes.
Defines your organisation capability to procure,distribute, and manage the licenses needed for IT systems, services, and software. The serve consumption model requires that teams develop new skills for procurement and license management and new processes for evaluating license needs.
The service delivery models that present the most software-licensing challenges are infrastructure as a service (IaaS) and platform as a service (PaaS). Software as a service (SaaS) is less likely to cause problems because, as the name suggests, the software is part of the cloud provider’s services. With IaaS and PaaS, though, the customer has shared control over what is run in the cloud environment, including third-party software. In the case of IaaS, the customer does not manage or control the underlying cloud infrastructure but may have control over operating systems and deployed applications. With PaaS, while the customer typically doesn’t have control over the operating system, it may have control over the deployed applications.
Where the complexity comes in is that software manufacturers are all over the map in how they address cloud use in their software licenses. Some base their licensing on the number of users, and those users in turn may be named or concurrent. Others charge per processor or core that the software runs on. Still others look at actual usage, a metric that is distinct from number of users. The one thing that these various licensing models have in common is that they are attempts to maximize revenue, and naturally, software makers view the use of their products in the cloud as an expansion of licensing rights that represents an opportunity for increased revenue.
Can the customer argue that the cloud does not represent an expansion of licensing rights? It would be difficult. If the customer acquired its software licenses from the vendor under a long-standing agreement, chances are good that the agreement pre-dates the inception of cloud computing. Of course, contracts generally do not address technology offerings that don’t exist at the time of the contract’s drafting, so a pre-cloud software-licensing contract is highly unlikely to contemplate the use of those licenses in a cloud environment. Legally, any rights that aren’t explicitly stated as being granted to the customer in the license agreement are retained by the software manufacturer. In cases like this, customers do not have any pre-existing rights to use their software licenses in the cloud.
Parsing the clauses
To better understand the challenges that the cloud brings to software licensing, it might be helpful to take a look at some clauses that one might see in a cloud vendor’s contract. Below are four, followed by my explanation of what they mean and why they’re pertinent.
Customer authorizes [VENDOR] to copy, install and modify, when necessary and as required by this Agreement, all third-party software to be used in the Services.
What this means: As part of providing the service, the cloud vendor may need to access the software in order to create redundant systems, and potentially to replicate or restore the customer environment in the event of an unplanned outage or other disaster. The above language says that the customer gives the cloud vendor permission to do these things on its behalf.
Customer warrants to [VENDOR] that it has obtained any licenses or approvals required to give [VENDOR] such rights or licenses to access, copy, distribute, use and/or modify or install any third-party software to be used in the Services.
What this means: This affirms that the customer’s license agreement with the software manufacturer includes the rights for the cloud vendor to access the software in the manner described above.
Some third-party software manufacturers’ contract terms and conditions may become void if [VENDOR] provides services for or works on the software (such as providing maintenance services). [VENDOR] DOES NOT TAKE RESPONSIBILITY FOR THIRD-PARTY WARRANTIES OR FOR ANY EFFECT THAT THE [VENDOR’S] SERVICES MAY HAVE ON THOSE WARRANTIES.
What this means: The cloud vendor is saying that if its use of the software in providing the services causes any noncompliance with the terms of the software-license agreement, then the cloud vendor is not responsible for any adverse consequences.
Third-party software shall be exclusively subject to the terms and conditions between the third-party software provider and Customer. [VENDOR] shall have no liability for third-party software.
What this means: The cloud vendor is saying that it has no responsibility regarding the effective functioning of the software, or any adverse impacts of any malfunctioning of the software.
All this adds up to the fact that you need to clearly identify your license rights and usage needs before deploying third-party software in the cloud, then effectively capture those in your contract with the cloud vendor.
Helps stakeholders understand how to update staff skills and organizational processes necessary to deliver, maintain, and optimize cloud solutions and services.
Common Roles: CTO; IT Managers; Solution Architects.
IT architects and designers use a variety of architectural dimensions and models to understand and communicate the nature of IT systems and their relationships. Organizations use the capabilities of the Platform Perspective to describe the structure and design of all types of cloud architectures. With information derived using this Perspective, you can describe the architecture of the target state environment in detail. The Platform Perspective includes principles and patterns for implementing new solutions on the cloud, and migrating on-premises workloads to the cloud.
Encompasses the organisation capability to provide processing and memory in support of enterprise applications. The skills and processes necessary to provision cloud services are very different from the skills and processes needed to provision physical hardware and manage data centre facilities. Many processes move from being focused on real-world logistics to being focused on virtual and fully automated processes.
Addresses the organisation capability to provide computing networks to support enterprise applications. Moving from hardware components to a networks of delivered services changes network provisioning significantly, and teams will need to develop new skills and processes to design, implement, and manage this transition.
Focuses on the organisation capability to provide storage in support of enterprise applications. Storage provisioning in the cloud is accomplished with cloud-based block and file storage. The skills and processes required to provision these services are significantly different from provisioning the physical storage area network (SAN), network-attached storage (NAS), and disk drives.
The Problem With Legacy Storage Provisioning
This need for better storage provisioning capabilities has lead the storage suppliers in the industry to add storage virtualisation capabilities to their legacy storage systems. But this virtualisation is often internal, meaning it is isolated to a single system and a single manufacturer. Internal storage virtualisation has simplified, to a degree, the storage provisioning process by allowing an administrator to simply select the size of the partition and letting the storage system do more of the work. With internal virtualisation the administrator will still receive every storage request, analyse the request and know where to provision that storage from. All of which becomes a bottleneck to service delivery.
It also leads to having multiple storage virtualisation software instances running as each system from each manufacturer has its own software that needs to be learned and interacted with. The CSP/MSP typically has a wide collection of storage hardware. This would be similar to having a different brand hypervisor loaded on every server and having to manage each of those separately.
Legacy provisioning as it is provided by internal storage virtualisation also requires that the administrator know which type of storage and storage system from which the provisioning will occur. The administrator needs to make the physical connection between the performance needs of the application and the storage environment’s available storage media types. They must know which media types and systems are best suited for each type of request.
Provisioning is More Than Capacity
The current internal storage virtualisation capabilities found in legacy systems are limited to the provisioning of capacity. Storage, like servers, has more than just one resource and applications will use those resources differently depending on the situation. Storage resources include the storage CPU, storage controller memory, internal cache management and network bandwidth in addition to physical capacity required. The combination and control of these resources represent the amount of IOPS (input/output operations per second) or throughput and storage latency that a storage system can deliver. But as is the case with storage capacity not all servers or applications need the same amount of IOPS or storage latency. Legacy storage systems simply don’t provide a granular way to allocate performance within a storage system.
The lack of the ability to provision performance plagues even more modern storage systems as well as storage virtualisation software that claims to be designed for the highly visualised data centre. Reality is that these systems may be appropriate for those situations but are not able to meet the provisioning needs of the CSP/MSP.
Provision Requirements of the CSP/MSP
The CSP/MSP is foreshadowing what the enterprise will become in the near future; a data centre that is judged on its ability to respond rapidly to an ever growing and ever demanding user base. In the case of a CSP/MSP these “users” are accounts that pay a monthly fee and have specific service level agreements (SLA) requirements of the CSP/MSP. The speed at which provisioning can be performed and the ability for that provisioning rule to be maintained over time is the foundational component in meeting those SLAs.
Self-Serviced Provisioning
For the CSP/MSP to be profitable they cannot afford to hire administrators every time a new account is brought on or even after 100 accounts are brought on. Instead they need to be able to safely delegate provisioning to the account while maintaining oversight. This means allocating a certain amount of capacity and IOPS/throughput/latency per account and then allowing the account to divide up those services based on need.
Self monitoring also may be a need in many cases. The account wants to know how much he is using on which application at what time. This will help them to better manage their applications running at a CSP/MSP.
Manages User’s Expectations
A key challenge with not being able to provision IOPS in legacy systems is that the performance experience can not be controlled. This creates an expectations problem because users that sign up for a bronze service level get the same performance experience that a gold service level gets.
Even if different class systems are used to allocate the performance resources, the first set of users on a system will experience a higher than promised level of performance and then see their performance degrade as more accounts are added to a system. The CSP/MSP needs the ability to guarantee a certain level of performance, no more, no less, so that users expectations can be managed.
This level of performance needs to remain constant, so the performance that the user sees from their assigned storage is the same today as it will be a year from now. Changes to the environment and even the storage system itself should not impact the user nor jeopardize the SLA.
Efficient Provisioning
The MSP/CSP needs to balance the cost advantages of maximizing storage resources with the customer satisfaction risks associated with extending a system too far. They need a storage system that will allow them to granularly assign capacity and performance resources so that these systems can be taken to their maximum capabilities without risking customer satisfaction.
Essentially each available GB and IOPS needs to be bought and paid for prior to investing in an additional system. This allows the addition of new storage investment to be trended based on the rate that resources are being consumed on present systems. In short the storage environment needs to scale like the CSP/MSPs business scales.
When a customer or account demands storage with varying levels of performance and capacity, they may need to be provisioned from different storage systems. The administrator needs to know which storage system has how much capacity and performance left out. When manually managed by the administrator, storage fragmentation occurs, usually.
Storage fragmentation is a phenomenon in which large number of storage systems have the ability to provide a certain type of storage but none of the storage system is capable of providing one type of storage. For example, if there are 10 storage systems in the infrastructure and the CSP/MSP admin provisions 5TB/1000 IOPS volumes equally on all of them, when the system is 70% full, it may not be possible to provision 5TB/20000 IOPS, as this needs writing across large number of disks, but the disks are 70% full. Intelligent and automated provisioning guidelines will help avoid such a scenario.
Multi-Vendor, Multi-Tier Provisioning
CSP/MSP also need the storage system to provide this provisioning along with other storage services like thin provisioning, snapshots, cloning and replication, across multiple storage platforms, even those from different vendors. This allows the CSP/MSP to manage their entire storage environment from a single interface regardless of the manufacturer of the individual platform. Performance can then be allocated intelligently across platforms by finding the storage system with the storage resources that best match the IOPS requirement. It also saves the MSP/CSP from the vendor lock in associated with buying a single vendors system, giving them flexibility to select storage systems based on suitability to the task at hand.
Introducing Elastic Provisioning
Elastic provisioning is the ability to provision both capacity and performance resources data centre wide from a single interface. It models the server virtualisation concept by deploying a series of off the shelf servers to act as physical storage controllers. The storage in the environment is then assigned to these storage controllers. Since these controllers are abstracted from the physical storage they can manage a mixed storage vendor environment.
Elastic storage provides the ability to spawn virtual controllers similar to how a server host spawns virtual servers. Each of these virtual controllers is assigned to an account. Capacity and IOPS/Throughput/Latency, based on the needs of the account, are then assigned to the virtual controller. The account can then sub-divide the capacity and SLA parameters based on the needs of each of its applications.
This virtual controller functionality ensures that a misbehaving application at one account won’t impact the capacity or performance needs of another account. There is complete isolation. It also insures that data can be segregated between accounts, another common concern in the CSP/MSP.
From CSP to the Enterprise
It is easy to see how the enterprise could leverage these capabilities as well. Instead of accounts, different lines of business or application groups could be assigned virtual storage controllers. Those groups could then manage their own storage without risk to the other groups. As is the case with CSP/MSPs the enterprise also has a mix of storage systems and could benefit from a centralized controller cluster.
Summary
Provisioning of storage remains a key challenge in data centers of all types and sizes but it is especially problematic for the CSP/MSP. It becomes THE bottleneck in rapidly responding to customer requests and its limitations make it difficult to guarantee long term adherence to SLAs. Elastic provisioning is a viable solution to this problem. It provides for multi-vendor provisioning of both capacity and performance resources.
Addresses the organisation capability to provide database and database management systems in support of enterprise applications. The skills and processes supporting this capability change significantly from managing hardware-bound and cost-bound databases to provisioning standard relational database management systems (RDMS) in the cloud and leveraging cloud-native databases.
Database provisioning for development work isn’t always easy. The better that development teams meet business demands for rapid delivery and high quality, the more complex become the requirements for the work of development and testing. More databases are required for testing and development, and they need to be more rapidly kept current. Data and loading needs to match more closely what is in production.
When more than one developer is working on a development database, it is wise to ensure that developers can easily set up, or provision, their own versions of the current build of the database as a part of having an isolated development environment. By providing a separate copy of the current version of the database, it is easier to ensure that any one person working on code doesn’t break the work being done by others. This goes some way to support a DevOps approach to database development. It doesn’t remove the need for integration and integration testing, but it improves the individual developer’s ability to get work done unhindered by the overhead of team-based database development.
Provisioning any type of server environment for this type of isolated development is tricky, whether it involves web servers, active domains or email servers, but when we add databases to the provisioning story, as with just about everything with databases, the situation becomes more challenging.
Challenges of Provisioning Database
As soon as you start to automate the process of creating databases for developers you’re going to hit a number of issues. Each of these makes it more difficult to create an automated, hopefully self-service, method of provisioning a database. Ideally, you’d like the developers to manage this themselves via an automated system but there are plenty of roadblocks on the route to that Eldorado.
Size of Database
It is quick and easy to automate the simple process of creating an empty database. However, the production environment will never involve just an empty database, and the developer will have to be certain that the database will work with a volume of data with the same characteristics, distribution and size as the production data. Basically, you’re going to need that sort of data for at least part of the development process. That data is going to have to be at least representative of your production data, though you’d be unlikely to be able to use a copy of it (see more on Production Data in the section below). This means you’re moving more than a few rows. Most databases these days are at least hundreds of gigabytes in size and may run into many terabytes or more.
The size of the data presents two immediate challenges to provisioning. First, you need to have the space available to provide this for each of the developers. For relatively small databases of 20-50gb, this is no big deal nowadays, but the more production-like the volume of data gets to be, the larger the size of disk-space required. Second, as the sizes increase, it makes provisioning slower and slower in an almost linear fashion. Restoring or migrating more data simply takes more time.
Timing of Provisioning Refresh
When you have several developers working on a single development database, but working with different parts of that database in varying degrees of completion for any given piece of functionality, one developer may want to check in his work and get a fresh build of the database, while the others haven’t completed their code or even set up adequate unit testing for the new functionality yet and need to remain on the current version increment of the database. Add in a testing team or even multiple development teams and this problem multiplies. You could just hope that they are all happy with the same set of data, but what if someone needs an extreme version for scalability tests, or run integration tests on a process, using a known input set of data?
As long as the individual is responsible for their own database, they can largely ignore the current status of other databases, however, as soon as integration has to occur, multiple versions of test data, structures or code could cause severe difficulty.
Production Data
In theory, the very best data for testing aspects of the functionality to ensure that it will work when the code gets to production is the data from production. However, data is becoming more and more tightly regulated, up to and including the actual threat of prison time for intentionally sharing data with unauthorized people.
Even if there were no need for regulatory compliance, it would be crazy to allow your developers to have production data on their development laptops. These are likely to leave the building regularly and could be, and often are, lost or stolen. The information managed within these databases defines many modern businesses, so losing something like a database of customers to the competition could be crippling.
You could easily imagine that you just need to mask the data, to render it compliant. The problem with this is that you would need to mask the data without affecting its distribution. The reason for wanting to use production data in the first place is because of its size and distribution. If you change the way it is distributed as well as the actual values then what is its’ value? It may not respond to queries in the same way.
Necessary Provisioning Requirements for Databases
On top of the problems with data, there are requirements that must be met within a standard development and deployment process in support of more accurate and faster development.
Clean Data
The data that gets distributed through the provisioning process must be clean. Not just for reasons of legal compliance, although, of course, that also applies. Instead, we’re cleaning the data in order to be sure that our tests will work smoothly and accurately. For example, if you’re testing email from the application, you want the email information stored within the database to be an email address that can be checked as part of the testing process in order to validate that things are working end-to-end. This means that the data within the provisioned database will have to be modified to reflect the needs of the testing.
Accurate Distribution
Although you may want to use masked or obfuscated production data in order to meet clean data requirements or answer regulatory limits, that doesn’t mean that you can simply update all the information to a single string. This will ruin any special types of data distribution that occurs in production. In order to provide meaningful testing data, the replacement process should provide a means of ensuring that the replacement data is similar to that which is being replaced. Without this you could have indexes with a single value or statistics that are radically skewed differently to your production servers.
Methods for Meeting Challenges and Requirements
Although it is difficult to meet the challenges and requirements for database provisioning, it’s not impossible. Virtualization and containerization technologies can help. For example, a new Redgate tool, SQL Clone, builds on standard disk virtualization technologies in Windows to allow us to create a database ‘clone’ that behaves just like a normal database, but has a vastly smaller footprint. Generally though, you just have to approach this problem in the same way you do other problems within your database management system.
Automation
The first and most important aspect of ensuring a fast, accurate, repeatable provisioning process, as well as possibly supplying a mechanism of self-service is to use automation. You must automate the database clean-up. From there you have to automate the mechanisms for refreshing the database to your development and test systems (probably taking advantage of some type of restore). By automating all these steps you can ensure that they will work the same way every time. If you build a script to cleanse data, you’ll be sure that the data is clean, every time. Just be sure that your data manipulation processes run in an atomic fashion, meaning, all or nothing on the commit so that you don’t accidently release production data to the development environment.
Communication
Everyone should know what the process is, how it works, and, most importantly, how often you’re updating the root provisioning database. This is vital. Everyone needs to understand the process so that they know where to go to get the database and so that the business and the auditors know that you’re protecting the production system. Everyone must know how the process works in order to be able to help with adjusting process over time as needs and requirements change or additional checks, tests, data modifications and data masking are added. Finally, everyone needs to know how frequently the provisioning is set up in order to appropriately schedule their own activities.
Conclusion
While provisioning for databases certainly has a large number of challenges, many of them can be overcome through careful communication and precise automation. Through these means you should be able to automate preparation of a provisioning database and, possibly, provide a means of self-service in order to support your DevOps processes within the database in as efficient a fashion as possible.
Encompasses the organisation capability to define and describe the design of a system and to create architecture standards for the organisation. With cloud services, many of the traditional architectural aspects of systems change. Architects will need to develop new skills to codify architectures in templates and create new processes for workload optimization.
IT ARCHITECTURE CHEAT SHEET
When planning and implementing your IT architecture, ease the process by reviewing critical information: major IT architecture concepts such as common IT architecture tasks, standardizing technology, and consolidating and centralizing technology resources; collaboration solutions to institute across the enterprise; and system maintenance processes that can be automated to help you increase savings and reduce administrative overhead.
IDENTIFYING COMMON IT ARCHITECTURE TASKS
Taking on an IT architecture project means dealing with myriad detailed tasks. No matter the nature of your IT architecture project, however, be sure to cover this abbreviated checklist of common, high-level tasks:
-
Eliminate resource silos: Getting rid of separate information resource silos through consolidation and centralization makes many other projects possible.
-
Identify data requirements: Determine the type of data your organization uses, its location and users, as well as any associated business requirements.
-
Identify and integrate existing resources: Identify resources currently in use and determine whether they should be integrated into the new architecture, replaced with an alternate solution, or retired.
-
Define technical standards: Define the rules and guidelines that your organization will use when making decisions regarding information technology.
-
Identify security requirements: Implementation can’t start until the security requirements have been identified. Remember, information is an asset to be protected.
-
Justify changes: Ensure that changes provide value to your organization in some fashion.
IT ARCHITECTURE: STANDARDIZING TECHNOLOGY
Standardization of technology is a common part of IT architecture projects. A standardized technology reduces complexity and offers benefits such as cost savings through economy of scale, ease of integration, improved efficiency, greater support options, and simplification of future control. Some common targets for standardization include
-
User workstation environments: This includes desktop hardware, operating system, and user productivity suites.
-
Software development: Consider standardizing not only programming languages, but also software development practices.
-
Database management systems: Try to standardize on a single database platform, such as Oracle, Microsoft SQL, mySQL, or PostgreSQL.
IT ARCHITECTURE: CONSOLIDATING AND CENTRALIZING TECHNOLOGY RESOURCES
A good IT architecture plan improves efficiencies. When your IT architecture program includes consolidation and centralization of technology resources, particularly in the data center, you gain improved resource use, document recovery, security, and service delivery; increased data availability; and reduced complexity. Some elements that you can consolidate or centralize include
-
IT personnel: Consolidate IT personnel into centrally managed, focused support groups based on need and skill sets.
-
Servers: The number of physical servers can be reduced by implementing virtualization or simply eliminating redundant functionality.
-
File storage: Get local file repositories off multiple file servers and onto a centralized storage solution such as a storage area network (SAN).
-
Directory services: Provide a common directory service for authentication or implement a single sign-on or federated authentication solution to bridge multiple directories.
IT ARCHITECTURE: COLLABORATING ACROSS THE ENTERPRISE
Collaboration solutions facilitate IT architecture teamwork by allowing team members to communicate, share data, and create repositories of collective intelligence, regardless of location or scheduling complications. They may decrease travel and telephone costs significantly. In IT architecture, common collaboration solutions include
-
Social networking: Social networking tools, such as chat, blogs, and forums, provide new and flexible methods for sharing information.
-
Groupware: Groupware allows employees to work together regardless of location by using integrated tools that facilitate communication, conferencing, and collaborative management.
-
Enterprise portal: Portals aggregate content from multiple sources, bringing it all into one place for easy access and creating a single point of contact.
IT ARCHITECTURE: AUTOMATING SYSTEM MAINTENANCE
Part of IT architecture includes improving efficiencies by restructuring enterprise resources. The more system maintenance processes that you automate in the IT architecture, the greater cost savings you can realize from reduced administrative overhead and support.
-
Operating system patches/updates: Most operating systems have some type of native automated patch management solution, and third-party solutions are also available.
-
Application updates: Some applications have the ability to update themselves automatically, while others may be updated through logon scripts or push technology.
-
Anti-malware updates and scans: Use enterprise-level anti-malware solutions that update frequently and scan regularly to improve security.
Defines the organization’s capability to customizeor develop applications to support your organization’s business goals. New skills and processes for Continuous Integration and Continuous Deployment (CI/CD) are a critical part of designing applications that take advantage of cloud services and the agility promised by cloud computing.
Development is a coordinated set of actions to capture requirements based on business needs, to implement a feasible solution, and to deploy it to users. All these actions need to be done according to agreed development practices within the given scope of time, resources and value creation expectations. Development can be a continuous flow of changes or, in larger and more complex cases, project-based.
DevOps
DevOps is the union of people, process, and products to enable continuous delivery of value to our end users. The contraction of “Dev” and “Ops” refers to replacing siloed Development and Operations to create multidisciplinary teams that now work together with shared and efficient practices and tools. Essential DevOps practices include agile planning, continuous integration, continuous delivery, and monitoring of applications.
Getting to DevOps
Be not afraid of DevOps. Some teams are born to DevOps; some achieve DevOps; others have DevOps thrust upon them.3 What is DevOps? Why does DevOps matter? Why now? How do you achieve DevOps successfully? Those are the topics we’d like to look at.
Understand your Cycle Time
Let’s start with a basic assumption about software development. We’ll describe it with the OODA loop.4 Originally designed to keep fighter pilots form being shot out of the sky, the OODA loop is a good way to think about staying ahead of your competitors. You start with observation of business, market, needs, current user behavior, and available telemetry data. Then you orient with the enumeration of options for what you can deliver, perhaps with experiments. Next you decide what to pursue, and you act by delivering working software to real users. All of this occurs in some cycle time.

Become Data-Informed
Hopefully, you use data to inform what to do in your next cycle. Many experience reports tell us that roughly one-third of the deployments will have negative business results, roughly one third will have positive results, and one third will make no difference. Ideally, you would like to fail fast on those that don’t advance the business and double down on those that support the business. Sometimes this is called pivot or persevere.
Strive for Validated Learning
How quickly you can fail fast or double down is determined by how long that loop takes, or in lean terms, by your cycle time. Your cycle time determines how quickly you can gather feedback to determine what happens in the next loop. The feedback that you gather with each cycle should be real, actionable data. This is called validated learning.
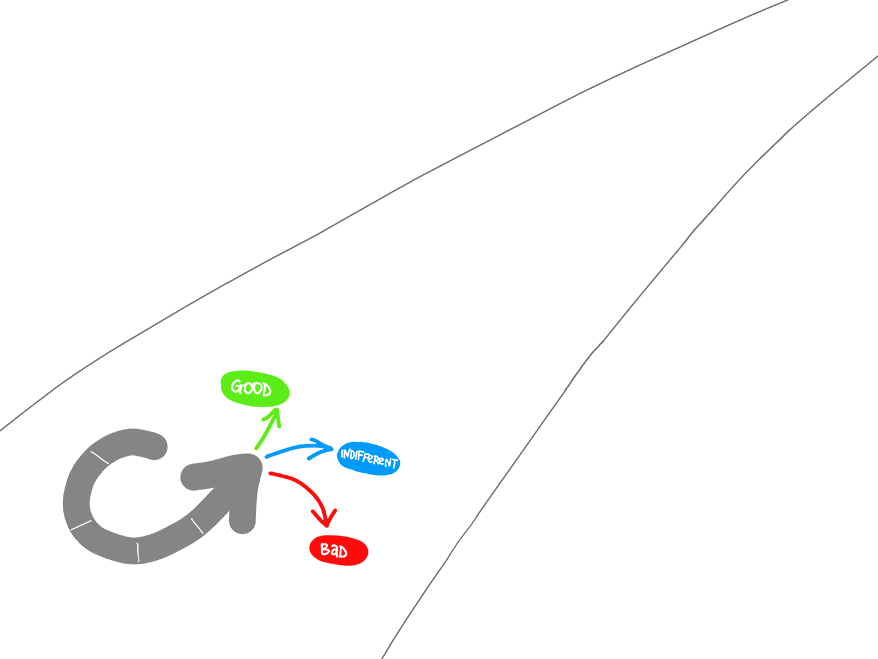
Strive for Validated Learning
Shorten Your Cycle Time When you adopt DevOps practices, you shorten your cycle time by working in smaller batches, using more automation, hardening your release pipeline, improving your telemetry, and deploying more frequently. [6]
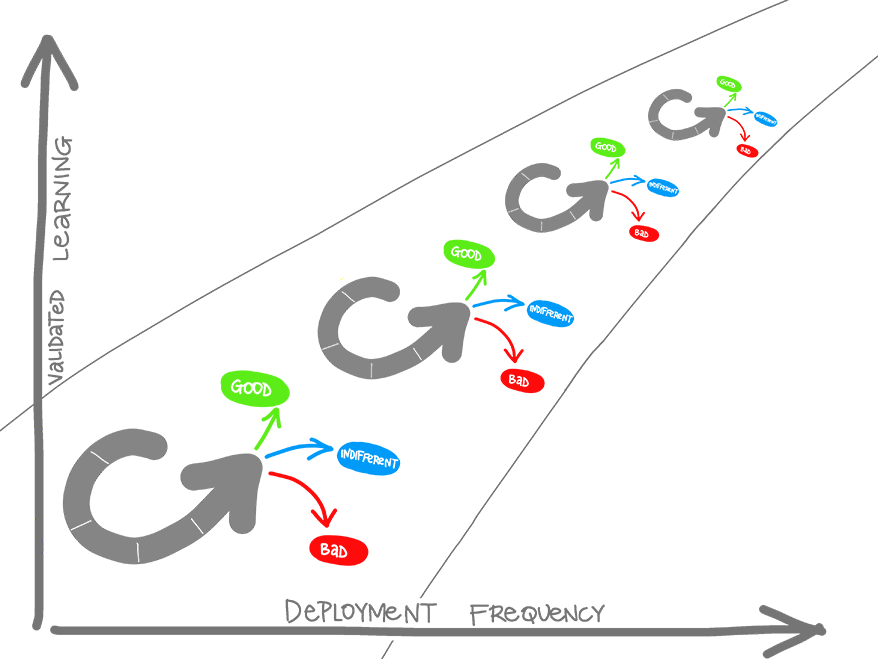
Shorten Your Cycle Time
Optimize Validated Learning The more frequently you deploy, the more can experiment, the more opportunity you have to pivot or persevere, and to gain validated learning each cycle. This acceleration in validated learning is the value of improvement. Think of it as the sum of improvements that you achieve and the failures that you avoid.
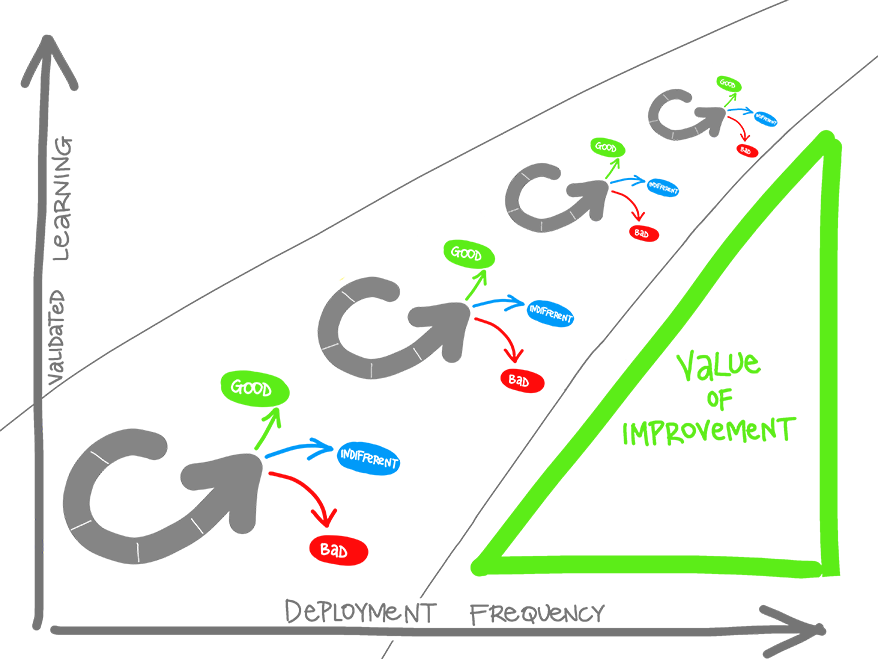
Provides guidance for stakeholders responsible for staff skills and organisational processes necessary to ensure that the workloads deployed or developed in the cloud align to the organisation security control, resiliency, and compliance requirements.
Common Roles: CISO; IT Security Managers; IT Security Analysts; Head of Audit and Compliance.
The Security Perspective helps you structure the selection and implementation of security controls that meet your organisation needs. All cloud customers benefit from a data centre and network architecture built to satisfy the requirements of the most security-sensitive organizations. Cloud providers offer hundreds of services and features to help organizations meet their security objectives for visibility, auditability, control, and agility. This perspective organizes the capabilities that will help drive the transformation of your organisation security culture.
Managing risk
Every IT organisation should take cybersecurity serious, to help we identified the flowing items.
Identification (ID): Develop the organizational understanding to manage cybersecurity risk to systems, assets, data, and capabilities.
- ID.01: Policies and Standards
- ID.02: Information Classification & Labelling
- ID.03: Discovery Scanning
- ID.04: Asset & Configuration Management
- ID.05: Penetration Testing Service
- ID.06: Threat Intelligence Service
- ID.07: Industry Standard Certification
- ID.08: GDPR
- ID.09: Business Impact Analysis
Protect (PR): Develop and implement the appropriate safeguards to ensure delivery of critical infrastructure services.
- PR.01: VPN Service
- PR.02: Modern Authentication Service
- PR.03: Conditional Access Service
- PR.04: Laptop Endpoint Protection (LEP incl. Server)
- PR.05: Cloud Access Security Broker Service (CASB)
- PR.06: Data Loss Prevention Service (DLP)
- PR.07: Identity/entity Management & Entitlement Management
- PR.08: Network Segregation & Zoning
- PR.09: Privileged Access Management Service (PAM)
- PR.10: Access Control Model
- PR.11: Multi Factor Authentication Service (MFA)
- PR.12: System (endpoint/server) Hardening
- PR.13: System / Application Certification
- PR.14: Endpoint Content Filtering Service
- PR.15: VIP Cyber Security Service
- PR.16: Global Firewall Management Service
- PR.17: Industry Standard Certification (ISO27001)
- PR.18: Encryption and key management
- PR.19: Patch Management Service
- PR.20: Physical environment protection
Detect (DE): Develop and implement the appropriate activities to identify the occurrence of a cybersecurity event
- DE.01: Vulnerability Management
- DE.02: Advanced Threat Protection
- DE.03: Intrusion Detection Service
- DE.04: Security Monitoring
- DE.05: Identity Analytics & Intelligence
- DE.06: Physical environment monitoring
Respond (RS): Develop and implement the appropriate activities to take action regarding a detected cybersecurity event
- RS.01: Incident Response Service
- RS.02: Security Operation
Recover (RC): Develop and implement the appropriate activities to maintain plans for resilience and to restore any capabilities or services that were impaired due to a cybersecurity event
- RC.01: Disaster Recovery Plan
- RC.02: Business Continuity Plan
This capability enables you to create multiple access control mechanisms and manage the permissions for each of these within your Cloud Account. Privileges must be granted before your user community can provision or orchestrate resources.
Cloud provides the capability for native logging as well as services that you can leverage to provide greater visibility near to real time for occurrences in the Cloud environment. Correlating the logs from cloud sources with other event sources like operating systems, applications, and databases can provide a robust security posture and enhance visibility. Consider integrating Cloud logging features into centralized logging and monitoring solutions to provide holistic visibility near to real time for occurrences in the Cloud environment.
Your environment can be defined and adjusted to evolve with your workload and business requirements. This capability provides the opportunity to shape your cloud security controls in an agile fashion; automating your ability to build, deploy, and operate your security infrastructure. As new security features become available in Cloud, it is important that your organisation IT Security teams update their skills and processes so that they can leverage these new features.
Addresses the capability for maintaining visibility and control over data, and how it is accessed and used in the organization.
Focuses on the organisation capability to respond, manage, reduce harm, and restore operations during and after a security incident. With Cloud, you have services and independent software vendor (ISV) solutions available to help you automate incident response and recovery, and to mitigate portions of disaster recovery. As you implement your cloud security, it is possible to shift the primary focus of the security team from response to performing forensics and root cause analysis.
Helps stakeholders understand how to update staff skills and organizational processes necessary to ensure system health and reliability through the move to the cloud, and as an agile, ongoing, cloud computing best practice.
Common Roles: IT Operations Managers; IT Support Managers.
The Operations Perspective describes the focus areas that are used to enable, run, use, operate, and recover IT workloads to the level that is agreed upon with your business stakeholders. Every organization has an operations group that defines how day-to-day, quarter-to-quarter, and year-to-year business will be conducted. IT operations must align with and support the operations of the business. Information gained through the Operations Perspective defines current operating procedures and identifies process changes and training needed to implement successful cloud adoption.
Addresses the organisation capability to detect and respond to issues with the health of IT services and enterprise applications. With cloud adoption, processes for both the detection of and response to service issues and application health issues can be highly automated, resulting in greater service up-time. Operations teams will need to develop new skills to leverage cloud features for service monitoring and automate many of their existing service monitoring processes.
Monitoring provides feedback from production. Monitoring delivers information about an applications performance and usage patterns.
One goal of monitoring is to achieve high availability by minimizing time to detect and time to mitigate (TTD, TTM). In other words, as soon as performance and other issues arise, rich diagnostic data about the issues are fed back to development teams via automated monitoring. That is TTD. DevOps teams act on the information to mitigate the issues as quickly as possible so that users are no longer affected. Thati s TTM. Resolution times are measured, and teams work to improve over time. After mitigation, teams work on how to remediate problems at root cause so that they do not recur. That time is measured as TTR.
A second goal of monitoring is to enable “validated learning” by tracking usage. The core concept of validated learning is that every deployment is an opportunity to track experimental results that support or diminish the hypotheses that led to the deployment. Tracking usage and differences between versions allows teams to measure the impact of change and drive business decisions. If a hypothesis is diminished, the team can “fail fast” or “pivot”. If the hypothesis is supported, then the team can double down or “persevere”. These data-informed decisions lead to new hypotheses and prioritization of the backlog.
“Telemetry” is the mechanism for collecting data from monitoring. Telemetry can use agents that are installed in the deployment environments, an SDK that relies on markers inserted into source code, server logging, or a combination of these. Typically, telemetry will distinguish between the data pipeline optimized for real-time alerting and dashboards and higher-volume data needed for troubleshooting or usage analytics.
“Synthetic monitoring” uses a consistent set of transactions to assess performance and availability. Synthetic transactions are predictable tests that have the advantage of allowing comparison from release to release in a highly predictable manner. Real User Monitoring (RUM), on the other hand, means measurement of experience from the user’s browser, mobile device or desktop, and accounts for “last mile” conditions such as cellular networks, internet routing, and caching. Unlike synthetics, RUM typically does not provide repeatable measurement over time.
Monitoring is often used to “test in production”. A well-monitored deployment streams the data about its health and performance so that the team can spot production incidents immediately. Combined with a Continuous Deployment Release Pipeline, monitoring will detect new anomalies and allow for prompt mitigation. This allows discovery of the “unknown unknowns” in application behavior that cannot be foreseen in pre-production environments.
Effective monitoring is essential to allow DevOps teams to deliver at speed, get feedback from production, and increase customers satisfaction, acquisition and retention.
Addresses the organisation capability to ensure application performance meets its defined requirements. Cloud services offer features to monitor and right-size the cloud services that you need to meet performance requirements. Operations teams need to update their skills and processes to ensure they are taking full advantage of these cloud features.
Addresses the capability to align the organisation assets in a way that provides the best, most cost-efficient service. Cloud adoption removes the need to manage hardware assets and the hardware life cycle. Organizations can simplify the management of software licensing by leveraging on-demand techniques that optimize license usage. Operations teams will need to update their skills and processes to ensure they can manage cloud assets.
Encompasses the organisation capability to manage, plan, and schedule changes to the IT environment. Traditional release management is a complex process that is slow to deploy and difficult to roll back. Cloud adoption provides the opportunity to leverage CI/CD techniques to rapidly manage releases and roll-backs.
Below you will find 8 essential steps to ensure your change initiative is successful.
-
Identify What Will Be Improved. Since most change occurs to improve a process, a product, or an outcome, it is critical to identify the focus and to clarify goals. This also involves identifying the resources and individuals that will facilitate the process and lead the endeavor. Most change systems acknowledge that knowing what to improve creates a solid foundation for clarity, ease, and successful implementation.
-
Present a Solid Business Case to Stakeholders. There are several layers of stakeholders that include upper management who both direct and finance the endeavor, champions of the process, and those who are directly charged with instituting the new normal. All have different expectations and experiences and there must be a high level of “buy-in” from across the spectrum. The process of onboarding the different constituents varies with each change framework, but all provide plans that call for the time, patience, and communication.
-
Plan for the Change. This is the “roadmap” that identifies the beginning, the route to be taken, and the destination. You will also integrate resources to be leveraged, the scope or objective, and costs into the plan. A critical element of planning is providing a multi-step process rather than sudden, unplanned “sweeping” changes. This involves outlining the project with clear steps with measurable targets, incentives, measurements, and analysis. For example, a well-planed and controlled change management process for IT services will dramatically reduce the impact of IT infrastructure changes on the business. There is also a universal caution to practice patience throughout this process and avoid shortcuts.
-
Provide Resources and Use Data for Evaluation. As part of the planning process, resource identification and funding are crucial elements. These can include infrastructure, equipment, and software systems. Also consider the tools needed for re-education, retraining, and rethinking priorities and practices. Many models identify data gathering and analysis as an underutilized element. The clarity of clear reporting on progress allows for better communication, proper and timely distribution of incentives, and measuring successes and milestones.
-
Communication. This is the “golden thread” that runs through the entire practice of change management. Identifying, planning, onboarding, and executing a good change management plan is dependent on good communication. There are psychological and sociological realities inherent in group cultures. Those already involved have established skill sets, knowledge, and experiences. But they also have pecking orders, territory, and corporate customs that need to be addressed. Providing clear and open lines of communication throughout the process is a critical element in all change modalities. The methods advocate transparency and two-way communication structures that provide avenues to vent frustrations, applaud what is working, and seamlessly change what doesn’t work.
-
Monitor and Manage Resistance, Dependencies, and Budgeting Risks. Resistance is a very normal part of change management, but it can threaten the success of a project. Most resistance occurs due to a fear of the unknown. It also occurs because there is a fair amount of risk associated with change – the risk of impacting dependencies, return on investment risks, and risks associated with allocating budget to something new. Anticipating and preparing for resistance by arming leadership with tools to manage it will aid in a smooth change lifecycle.
-
Celebrate Success. Recognizing milestone achievements is an essential part of any project. When managing a change through its lifecycle, it’s important to recognize the success of teams and individuals involved. This will help in the adoption of both your change management process as well as adoption of the change itself.
-
Review, Revise and Continuously Improve. As much as change is difficult and even painful, it is also an ongoing process. Even change management strategies are commonly adjusted throughout a project. Like communication, this should be woven through all steps to identify and remove roadblocks. And, like the need for resources and data, this process is only as good as the commitment to measurement and analysis.
Addresses the organisation capability to ensure compliance with your organisation reporting policies and to ensure ongoing analysis and reporting of performance against key KPIs such as service-level agreements (SLAs) and service-level expectations (SLEs). With cloud adoption, operations teams need to update their skills and processes to ensure that they are taking advantage of new features to provide better detail and granularity in their reporting and analytics.
Addresses the organisation capability to operate in the event of a significant failure of IT services and the capability to recover from those failures within the time parameters defined by your organisation. Many of the traditional BC/DR processes are significantly changed with cloud adoption and require operations teams to update their skills and capabilities to take advantage of the new models.
IT Service Catalog is the organisation capability to select, maintain, advertise, and deliver an SLA or set of IT services. With cloud adoption, the IT Service Catalog serves as a control mechanism to ensure that your organization selects the services that provide the best business value while minimizing business risk. It becomes closely coupled with Portfolio Management in the Governance Perspective in order to ensure that technical services are aligned to business goals and needs.
This article was developed with the purpose of proposing certain principles that must drive an enterprise architecture initiative. The main motivation that led to the development of this list is the difficulty of implementing enterprise architecture in an environment as hostile as the financial market. There is great pressure on the technology segment, which is usually not perceived as strategic. An even greater challenge is showing that IT decisions can add value and differentials to businesses.
Business
- Maximum benefits at the lowest costs and risks
- Compliance with standards and policies
- Control of technical diversity and suppliers
Talent
Demand
- Common terminology and data definitions
- IT and business alignment
Platform
- Easy-to-use applications
- Accessible information
- Adaptability and flexibility
- Adoption of the best practices for the market
- Adherence to functional domains
- Interoperability
- Low-coupling interfaces
- Convergence with the enterprise architecture
- Enterprise architecture also applies to external applications
- Shared information
- Component reusability and simplicity
- Technological independence
Security
- Information security
- Information treated as an asset
Operations
- Business continuity
- Changes based on requirements
This list was organized and developed based on the selection and adjustment of the most relevant principles established throughout my experience and linked to the 6 elements of the IT Framework. Most of these principles apply to any type of industry after only a few minor adjustments. Usually, there are around 20 enterprise architecture principles that must be followed. A very short list contains more generic and ethereal principles, hindering practical applications. On the other hand, an excessively extensive list is too specific and generates inconsistencies and conflicts between principles and changes resulting from technological, environmental, and contextual evolution.
Definitions
Principles are high-level definitions of fundamental values that guide the IT decision-making process, serving as a base for the IT architecture, development policies, and standards. The principles of architecture define general rules and guidelines to use and implement all information technology (IT) resources and assets throughout a company. They must reflect a level of consensus between several corporate components and areas, constituting the basis for future IT decisions. Each architecture principle must focus mainly on business goals and key architecture applications.
Format of each principle
Each principle must be formally stated. Some suggestions regarding the format in which principles must be stated are available in related literature. This article follows the format suggested by The Open Group Architecture Framework (TOGAF), in which each principle is presented according to the following format: Name The name must represent the essence of the rule and be easy to remember. Specific technology platforms must not be mentioned in a principle’s name or description.
Description
The description must succinctly and directly convey the fundamental rule. Most information management principle descriptions are similar among different companies.
Rationale
This must highlight business benefits generated by adhering to the principle, using business terminology. It must emphasize the similarity between information and technology principles and those that regulate business operations. The rationale must also describe its relationship to other principles and intentions compared to a balanced interpretation. It should describe situations in which a certain principle would outweigh another in the decision-making process.
Implications
This item must highlight requirements, both for businesses and IT, to comply with the principle regarding resources, costs, and activities or tasks. The impacts in businesses and consequences of adopting a principle must be detailed. Readers must be able to easily answer the following question: “How does this affect me?” It is important not to simplify, trivialize, or question the merit of such impacts. Some implications are exclusively identified as potential impacts, with a speculative characteristic as opposed to being fully analyzed.
Cloud Architect

Cloud Software Engineer

Cloud Relation Manager

Cloud Engineer

Cloud Service Developer

Cloud Systems Administrator

Cloud Analyst

Cloud Systems Engineer

Cloud Network Engineer

Cloud Product Manager

Duties: Perform product planning to help keep cloud-based offerings relevant and valuable to internal customers, including creating the product concept and strategy documents, updating requirement specifications, product positioning and sales process.
Education: BS in business or computer science or equivalent work experience. Advanced degrees preferred.
Skills: 3+ years experience working in a software development company that deploys with SaaS or cloud-based models. Strong communication skills.
Description:
As the product owner, you wear a lot of hats: product expert, backlog groomer, voice of the customer and more. You’re embedded in the agile team—interfacing between developers and customers, writing user stories, collaborating with testers on acceptance criteria and translating the product roadmap into a manageable product backlog. And you do all of this while putting the customer first, ensuring that customer value is at the heart of all decisions made by your agile team.
What Makes a Successful Product Owner
- Enjoy working with developers and be physically located near your dev team.
- Have a talent for engaging with users to discuss existing features.
- Be comfortable with the unpredictability that comes with software development—understanding that roadblocks tend to occur at the least convenient times.
- Be decisive and be able to make decisions based on limited data.
Cloud Scrum Master

Duties: Guide the product delivery width the other Cloud resources.
Education: BS in business or computer science or equivalent work experience.
Skills: Scrum Master Certified, Design Thinking Facilitator
Description:
The ScrumMaster is at the heart of the agile team—focused on the team itself and not the project. You continuously ensure your team stays on task and aligned with proper scrum workflows while providing guidance in best practices and motivation if things do not go as planned. And if your team experiences any roadblocks along the way, you—in all of your agile wisdom—help remove what’s in your team’s way to success.
Facilitators make Design Thinking work more productive. A team that has a well-trained design facilitator can come to a drastically different outcome. This individual understands what it takes to have a good ideation session, and comes prepared to the meeting to make it happen. She ups the energy level in the room with a “stoke”, a short exercise that gets the team members’ brains and bodies moving. She lays out the ground rules for the session and makes sure everyone has the proper tools. She guides the participants through the exercise, moving things along when idea creation slows down and picking out moments to slow down when she sees certain team members’ processing an idea. She also knows when to call the session to a close and to move onto the next phase in the design thinking process
UX designers determine the interaction experience the user encounters with a website, app, or software

Data Scientist

Duties: Data scientists deal with datasets that are far too large and complicated to open in Excel. Rather than limit themselves to tabs and sheets, data scientists use programming to work with whole databases that they manipulate to glean usable information.
Education: BS in business or computer science or equivalent work experience.
Skills: Data Analysis, Machine Learning, Modeling Techniques, & Big Data, Critical Thinking & Synthesis, Visualization, Presentation, & Reporting
Description:
THE SKILLS OF THE DATA SCIENTIST
Programming
Data scientists deal with datasets that are far too large and complicated to open in Excel. Rather than limit themselves to tabs and sheets, data scientists use programming to work with whole databases that they manipulate to glean usable information.
Data Analysis
There are two general ways to consider data analysis. You can either start with a problem and analyze data in an attempt to find the solution to that problem, or you can start with massive amounts of data and analyze it in search of specific trends that point to opportunities within the marketplace from which the dataset was derived. After either method, the data has to be cleaned up, formatted, and presented to teams of people in a way that can be understood and used by people who are not data scientists.
Predictive Modeling
Predictive modeling is what separates the data scientist from the data analyst. Data scientists are tasked with predicting the future using data from the past. For example, BuzzFeed wants to predict whether an article will go viral, so it gets a data scientist to look at the available data: past articles that have gone viral, most-searched words, etc. To mine that massive amount of data, the data scientist will use machine learning methods such as regressions, support vector machines, or decision trees to determine what kind of articles BuzzFeed should be writing and what keywords it should include to increase the probability of an article going viral.
THE TOOLS OF THE DATA SCIENTIST
Python & R
Python is a more practical approach to data science and a good language for beginners to learn. Python scripts are generally faster than working in R, and allow data scientists to connect data pipelines with web apps and frameworks used in modern production. R is more traditional and offers many niche models, but Python is better supported and has the benefit of scale.
Together, Python and R allow data scientists to build and automate much of their analysis. Python and R have functions and libraries that can run mathematical calculations on data to build descriptive and predictive models. Data scientists use Python and R to run, share, and distribute their work among colleagues and companies. For example, if a company is trying to predict the sales cycle of a product, it can use Python + data science methods to sort and filter incoming data, build an algorithmic model, and generate actionable insights.
SQL
SQL stands for “Structured Query Language,” and it’s the tool of choice for data analysis. Data scientists use SQL to organize their databases and pull specific subsets of data for analysis and modeling. While there are many types of databases — including some that don’t use SQL — SQL databases are by far the most common. SQL syntax is also the foundation for many of the tools used to work with “big data” systems like Hadoop.
Together, SQL, R, and Python give data scientists the power to acquire, sort, and mine data in order to build powerful predictive models.
Front End Developer
Duties: Front end developer is responsible for getting the data from the back end and displaying it in a way that users can navigate through it and access the required information.
Education: BS in business or computer science or equivalent work experience.
Skills: HTML, CSS, Javascript coding and programming skill
Description:
Front End Developer
The front end developer is the *artist who is responsible for getting the data from the back end and displaying it in a way that users can navigate through it and access the required information. The front end developer responsibilities are complex in nature, and he/she is mostly associated with the production, maintenance and modification of the organization’s websites as well as web application’s users interfaces. It is a significant position that requires programming skills and aesthetic sensitivity. If you are techno savvy person who loves working in a team environment with strong knowledge and command over HTML5, CSS3, Javascript, etc., then this is the perfect job for you.
Key Responsibilities of a Front End Developer
The front end developer should be able to convert the original visual designs and concepts into front end HTML code. He/she works in close association with the development team, designers, and information architects to realize and deliver the best web technology solutions. He/she needs to be fully aware of web development issues, strategies, and should be able to handle the front end development frameworks efficiently. He/she takes the support of the existing infrastructure and may develop new technologies to complete the given assignment successfully. He/she designs and develops new websites and reviews the scope of the work. To get a more clear and better picture, let us get some more detail information about the core responsibilities and duties that need to be carried out by this professional:
To maintain the existing websites and to create HTML markups as per the layouts provided by the designing team and to ensure its cross browser compatibility To work closely with the development team and style layouts as per the requirements To carry out the usability tests, audits and be involved in validation, debugging, accessibility as well as maintenance and supporting functions of the website To develop cross platform front ends in CSS, HTML, Javascript and to optimize it, to write the middle tier PHP code that is necessary for its support To understand the goals and objectives of the web team and use his/her expertise to bring in a new insight in the process of planning and designing To be able to quickly translate ideas and concepts by building dynamic, engaging and interactive websites by using the latest tools and technologies Apart from the above responsibilities, the front end web developer leverages the capabilities of the content management system and is actively involved in streamlining content, deploying, updating and maintaining it. He/she is responsible for incorporating the best practices and methods that would assist in search engine optimization. He/she adapts and monitors search optimization so that he/she is able to maintain results and visibility and adapt according to the changing needs of the organization. He/she ensures that the websites of the organization are developed in a way that are compliant with W3C standards. He/she should provide correct time estimates for the given projects and is involved in the technical specification and instructional documentation. He/she may need to train the non technical staff on some occasions. He/she remains updated with emerging technologies so that he/she is able to incorporate them and provide clients with innovative and best technological solutions.
Essential Skills
The front end developer should be well versed with HTML, CSS, Javascript coding and programming skills and should be eager and enthusiastic to learn about the latest technologies. He/she should pay strong attention to designing details and should be able to devise quick solutions for complex problems. Strong written as well as communication skills, good organizational skills, ability to switch and juggle multiple projects and meet deadlines, self starter, ability to work in a team as well as handle project individually are some of the other required skills.
Educational Requirements
The basic educational criteria to qualify for this post is that an individual should have completed an associate or bachelor’s degree in designing, interactive design, computer science etc. Those with higher education, updated technological knowledge and applicable experience would definitely have better chances for growth and development.
Back End Developer
Duties: Backend end developer is responsible for getting the data from the back end and displaying it in a way that users can navigate through it and access the required information.
Education: BS in business or computer science or equivalent work experience.
Skills: API Development and programming skill
Description:
Back End Developer
The Back End Developer (BED) programs within a scrum team where he will function as a key member of the Development team responsible for programing and back-end integration for the project. Working with the other team members in creating, iterating, presenting, and executing exceptional design solutions that exceed client expectations. In this role, the BED insures that :
- Maintain the central databases, ensure high performance, respond to requests from the front-end.
- Create a secure API for our web and mobile applications.
- Optimize the application for maximum speed and scalability.
- Implement security and data protection.
- Design and implement data storage solutions.
- Solid scalable software platforms from the ground up.
- Proper and innovative execution of work in all areas on schedule.
- Deliver a consistently superior creative product.
- A collaborative approach to the user-centered design process.
- Innovative solutions and experiences.
- Sound code.
The Requirements
- Bachelor’s Degree in computer science or equivalent education and experience.
- A minimum of 5 years’ experience in software engineering and/or architecture, preferably in a client-facing role.
- Experience with or strong familiarity with service-oriented architecture and its application to large software projects.
- Fluency in the principles of user-centered design methods, information architecture, usability, and interface and interaction design
- A broad portfolio of dev work demonstrating expertise in at least 2 major areas of UX design.
- A knowledge of the various software options used in the field for design and rapid prototyping (Adobe Creative Suite, OmniGraffle, and Axure)
- A firm grasp of a range of UX tools, processes, and outcomes
- Excellent written and verbal communication skills demonstrated through a comfortability in presenting work and actively gathering feedback, both internally and with clients
- An enthusiasm for keeping up to date on current topics in the field to inspire and inform client work and organizational culture
- Excellent organizational, time management, and multitasking capabilities
- Interest in and aptitude for creative business and marketing solutions
- Will make fun of my coding skills
- Self motivated and willing to expand knowledge
- Ability to self-manage while managing assigned teams and projects.
- Hands-on experience with various Amazon Web Services
- Capability to work on simultaneous projects and meet tight deadlines.
Responsibilities and Duties
The BED has four areas of responsibility (specific duties of each are explained below)
- Planning, Analyzing, Evaluating
- Develop workable budgets, work plans and realistic timetables.
- Collaborates with the FED, HOD, Head of Account Services, President, Head of Strategy and Head of Digital, on preparation of marketing recommendations, visual design strategies and actions for the client.
- Produce technical specs and original designs for new software products and services, based on client requirements and functional specs, in collaboration with other development and product team members.
- Demonstrate ability to recognize upcoming opportunities and threats to their delivery.
- Works with peers in the creation of project specifications and time plans.
- Assist in translating complex business requirements, user requirements, and specifications
- Contribute to all aspects of a project: requirements gathering, service development, front-end development, data design, overall architecture, QA, and/or server setup and administration.
- Development
- Proficiency with Git, a SQL database, and back-end programming languages.
- Experience in IoT projects, noSQL databases, Agile development, and machine learning is a plus.
Jekyll & Liquid Cheatsheet
A list of the most common functionalities in Jekyll (Liquid). 
You can use Jekyll with GitHub Pages, just make sure you are using the proper version.
Running
Running a local server for testing purposes:
jekyll serve
jekyll serve --watch --baseurl ''
Creating a final outcome (or for testing on a server):
jekyll build
jekyll build -w
The -w or --watch flag is for enabling auto-regeneration, the --baseurl '' one is useful for server testing.
Troubleshooting
On Windows you can get this error when building/serving:
Liquid Exception: incompatible character encodings: UTF-8 and IBM437 in index.html
You need to set the code-page first:
chcp 65001
Liquid
Output
Simple example of Output:
Hello {{name}}
Hello {{user.name}}
Hello {{ 'leszek' }}
Filtering output:
Word hello has {{ 'hello' | size }} letters!
Todat is {{ 'now' | date: "%Y %h" }}
Useful where filter example of getting single item from _data:
{% assign currentItem = site.data.foo | where:"slug","bar" %}
{{ newArray[0].name }}
Most common filters:
where– select elements from array with given property value:{{ site.posts | where:"category","foo" }}group_by– group elements from array by given property:{{ site.posts | group_by:"category" }}markdownify– convert markdown to HTMLjsonify– convert data to JSON:{{ site.data.dinosaurs | jsonify }}date– reformat a date (syntax reference)capitalize– capitalize words in the input sentencedowncase– convert an input string to lowercaseupcase– convert an input string to uppercasefirst– get the first element of the passed in arraylast– get the last element of the passed in arrayjoin– join elements of the array with certain character between themsort– sort elements of the array:{{ site.posts | sort: 'author' }}size– return the size of an array or stringstrip_newlines– strip all newlines (\n) from stringreplace– replace each occurrence:{{ 'foofoo' | replace:'foo','bar' }}replace_first– replace the first occurrence:{{ 'barbar' | replace_first:'bar','foo' }}remove– remove each occurrence:{{ 'foobarfoobar' | remove:'foo' }}remove_first– remove the first occurrence:{{ 'barbar' | remove_first:'bar' }}truncate– truncate a string down to x characterstruncatewords– truncate a string down to x wordsprepend– prepend a string:{{ 'bar' | prepend:'foo' }}append– append a string:{{ 'foo' | append:'bar' }}minus,plus,times,divided_by,modulo– working with numbers:{{ 4 | plus:2 }}split– split a string on a matching pattern:{{ "a~b" | split: '~' }}
Tags
Tags are used for the logic in your template.
Comments
For swallowing content.
We made 1 million dollars {% comment %} in losses {% endcomment %} this year
Raw / EndRaw
Disables tag processing.
{% raw %}
In Handlebars, {{ this }} will be HTML-escaped, but {{{ that }}} will not.
{% endraw %}
If / Else
Simple expression with if/unless, elsif [sic!] and else.
{% if user %}
Hello {{ user.name }}
{% elsif user.name == "The Dude" %}
Are you employed, sir?
{% else %}
Who are you?
{% endif %}
{% unless user.name == "leszek" and user.race == "human" %}
Hello non-human non-leszek
{% endunless %}
# array: [1,2,3]
{% if array contains 2 %}
array includes 2
{% endif %}
Case
For more conditions.
{% case condition %}
{% when 1 %}
hit 1
{% when 2 or 3 %}
hit 2 or 3
{% else %}
don't hit
{% endcase %}
For loop
Simple loop over a collection:
{% for item in array %}
{{ item }}
{% endfor %}
Simple loop with iteration:
{% for i in (1..10) %}
{{ i }}
{% endfor %}
There are helper variables for special occasions:
forloop.length– length of the entire for loopforloop.index– index of the current iterationforloop.index0– index of the current iteration (zero based)forloop.rindex– how many items are still left?forloop.rindex0– how many items are still left? (zero based)forloop.first– is this the first iteration?forloop.last– is this the last iteration?
Limit and offset starting collection:
# array: [1,2,3,4,5,6]
{% for item in array limit:2 offset:2 %}
{{ item }}
{% endfor %}
You can also reverse the loop:
{% for item in array reversed %}
...
{% endfor %}
Storing variables
Storing data in variables:
{% assign name = 'leszek' %}
Combining multiple strings into one variable:
{% capture full-name %}{{ name }} {{ surname }}{% endcapture %}
Permalinks
Permalinks are constructed with a template:
/:categories/:year/:month/:day/:title.html
These variables are available:
year– year from the filenameshort_year– same as above but without the centurymonth– month from the filenamei_month– same as above but without leading zerosday– day from the filenamei_day– same as above but without leading zerostitle– title from the filenamecategories– specified categories for the post
MOF
IT organizations are continuously challenged to deliver better IT services at lower cost in a turbulent environment. Several management frameworks have been developed to cope with this challenge, one of the best known being the IT Infrastructure Library (ITIL).